在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
大数据开发工程师需要学习哪些知识点?大数据程序员需要有坚实的大数据技术理论基础、了解数据平台、掌握数据存储HDFS、、日志解析及计算 MR、数据获取和预处理 Flume、结构化查询Hive、数据获取和预处理 Sqoop、大数据调度框架Azkaban、Scala编程基础等相关知识。

接下来我们具体来看看大数据开发工程师必备技能及相应要求:
一、大数据技术理论基础
大数据的起源和分类来深度解析大数据的起源和发展形态;云计算、人工智能。区块链等相关产业入手分析大数据与各大相关领域的关系;大数据管理系统架构、存储技术、书屋处理技术风方面详尽的讲解了大数据管理技术;电子商务、金融、行为等方面举例分析大数据的应用。从理论到实际案例帮助学员形成大数据初期思维。
二、数据平台
从大数据平台架构的演变、大数据平台的典型流程入手解析什么是大数据平台;从CAP原理、C10K问题,ACID vs BASE等方面分析大数据平台的设计考量;再从数据采集、数据存储、数据计算等方面以理论加实际案例的课程形式帮助学员深刻的理解大数据平台的应用。
三、数据存储 HDFS
大数据的核心技术:数据存储,主要内容涵盖:分布式文件系统、常用日志文件系统结构、Hadoop安装与运行环境测试、HDFS读写操作、海量数据存储常见解决方案等,旨在帮助学员建立数据存储知识体系结构,掌握常用数据存储方式,能够编写常用读写操作代码,并具备海量数据处理框架设计能力。
四、日志解析及计算 MR
从实战化的日志解析切入,MapReduce是基于Hadoop大数据技术的入门技能详细解刨MapReduce的各个环节,带领学员灵活定制高性能的MapReduce程序。旨在帮助学员能举一反三,对MapReduce的认识不仅仅停留在Map和Reduce两个函数上。
五、数据获取和预处理 Flume
解决海量数据的问题,众多大数据计算和分析技术应运而生。本课程首先从实际操作出发,就如何对分布式服务器的日志文件进行实时收集,并将其分流到不同存储介质进行详细说明;其次通过对Flume的设计原理、安装部署等方面系统的帮助学员了解Flume的理论、实际操作及应用;最后通过实际帮助学员帮助学员更深刻理解Flume。
六、结构化查询 Hive
解当前大数据领域主流数据仓库Hive的原理及使用,课程通过MapReduce的抽象化技术、Hive系统架构、Hive安装及调试、HiveSQL基础语法等基础理论,让学员能够全面了解Hive 是如何使用的,然后通过一个实战案例“UV查询”,带领大家在掌握理论的基础上,学会具体使用Hive。
六、数据获取和预处理 Sqoop
基于实际案例与理论数据深度解析静态系统的数据,其次全面系统的讲解了sqoop的安装及配置、架构分析以及sqoop的语法介绍,旨在帮助学员建立数据传送知识体系结构,掌握常用数据传送方式,并具备海量数据处理框架设计能力。最后列举网易云课堂sqoop案例帮助学员更精准的了解sqoop的应用。
七、大数据调度框架:Azkaban
深度解析开源调度系统azkaban,从系统介绍、安装配置、再到工作流调度实战、以及改进思路,全面的介绍任务调度系统的整体架构,一线案例的讲解加以实际演练帮助大家全方位掌握大数据调度系统。
八、Scala编程基础
Scala是一门多范式(multi-paradigm)的编程语言,集成了面向对象编程和函数式编程的各种特性。Scala 运行在Java虚拟机上,并兼容现有的Java程序。目前很多项目比如Spark, Kafka都使用Scala编写。Scala语言表述逻辑简单清晰,但是入门门槛比较高,学习难度大。这门课将带大家学习这门语言,为今后的编程和阅读源码打下基础。
九、Spark框架教学
Spark 是一种与 Hadoop 相似的开源集群计算环境,但是两者之间还存在一些不同之处,这些有用的不同之处使 Spark 在某些工作负载方面表现得更加优越,换句话说,Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
Spark 是在 Scala 语言中实现的,它将 Scala 用作其应用程序框架。与 Hadoop 不同,Spark 和 Scala 能够紧密集成,其中的 Scala 可以像操作本地集合对象一样轻松地操作分布式数据集。尽管创建 Spark 是为了支持分布式数据集上的迭代作业,但是实际上它是对 Hadoop 的补充,可以在 Hadoop 文件系统中并行运行。
大数据开发工程师要熟悉Linux开发环境,熟悉Shell命令,至少Java、python、scala中的一种编程语言;具备丰富的基于Hadoop、Map Reduce、Yarn、Storm、Spark、Hive、Hbase、kafka、Flume、HDFS、Spark Streaming等的大数据处理项目经验。每家公司对大数据岗位的要求不尽相同,结合自己擅长的领域找到与自己匹配的岗位。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
大数据开发工程师是做什么的?岗位要求高吗?
下一篇:
大数据Lambda架构概念及应用
相关推荐 更多

大数据Apache Hadoop YARN 工作原理介绍
Apache Hadoop YARN是一种新的 Hadoop 资源管理器,通用资源管理系统可为上层应用提供统一的资源管理和调度,引入为集群在利用率、资源统一管理和数据共享等方面具有很强的优势。
7642
2020-04-27 14:27:28
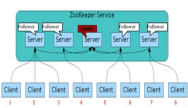
Zookeeper基本知识总结
本文为大家整理总结了Zookeeper的基本知识,主要内容有Zookeeper概述、ZooKeeper特性、ZooKeeper集群角色以及ZooKeeper集群搭建。下面一起来看看大数据学习中的干货知识吧~
6525
2020-06-11 19:12:50

Hadoop集群搭建过程总结
本文主要总结了Hadoop集群搭建的过程,内容包括发行版本说明、Hadoop集群简介、服务器准备、网络环境准备、服务器系统设置以及JDK 环境安装。有学习需要的小伙伴一起来看看吧~
8380
2020-06-18 15:32:40

大数据Hadoop生态体系中常见的子系统有哪些?
Hadoop是一个针对大量数据进行分布式处理的软件框架,是一个开发和运行处理大规模数据的软件平台,是Appach的一个用Java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算,具有可靠、高效、可伸缩的特点,很多程序会用到这个框架。
7255
2021-03-17 13:58:05

如何进入大数据领域,学习路线是什么?
想要从事大数据技术开发工作,请问要怎么做,路线是什么?从哪里开始学?学哪些? 废话不多说,直接上干货!
4986
2022-08-26 18:02:21



