在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
HDFS即Hadoop分布式文件系统。它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。那大数据中HDFS 存储的机制怎样的呢?

HDFS的存储机制主要从它的三个实体来说!
数据块
每个磁盘都有默认的数据块大小,这是磁盘进行读写的基本单位。构建于单个磁盘之上的文件系统通过磁盘块来管理该文件系统中的块。该文件系统中的块一般为磁盘块的整数倍。磁盘块一般为 512 字节。HDFS 也有块的概念,默认为64MB(一个map处理的数据大小)。HDFS上的文件也被划分为块大小的多个分块,与其他文件系统不同的是,HDFS 中小于一个块大小的文件不会占据整个块的空间。
HDFS用块存储带来的第一个明显的好处一个文件的大小可以大于网络中任意一个磁盘的容量,数据块可以利用磁盘中任意一个磁盘进行存储。第二个简化了系统的设计,将控制单元设置为块,可简化存储管理,计算单个磁盘能存储多少块就相对容易。同时也消除了对元数据的顾虑,如权限信息,可以由其他系统单独管理。
DataNode 节点
DataNode 是 HDFS 文件系统的工作节点,它们根据需要存储并检索数据块,受NameNode节点调度。并且定期向 NameNode 发送它们所存储的块的列表。
NameNode 节点
NameNode 管理 HDFS 文件系统的命名空间,它维护着文件系统树及整棵树的所有的文件及目录。这些文件以两个文件形式永久保存在本地磁盘上(命名空间镜像文件和编辑日志文件).NameNode 记录着每个文件中各个块所在的数据节点信息但并不永久保存这些块的位置信息,因为这些信息在系统启动时由数据节点重建。
没有 NameNode,文件系统将无法使用。如提供 NameNode 服务的机器损坏,文件系统上的所有文件丢失,我们就不能根据 DataNode 的块来重建文件。因此,对 NameNode 的容错非常重要。第一种机制,备份那些组成文件系统元数据持久状态的文件。通过配置使 NameNode在多个文件系统上保存元数据的持久状态或将数据写入本地磁盘的同时,写入一个远程挂载的网络文件系统。当然这些操作都是原子操作。第二种机制是运行一个辅助的 NameNode,它会保存合并后的命名空间镜像的副本,并在Name/Node发生故障时启用。但是辅助NameNode保存。态总是滞后于主力节点,所以在主节点全部失效后难免丢失数据。在这种情况下,一般把存储在远程挂载的网络文件系统的数据复制到辅助NameNode并作为新的主NameNode 运行。
大数据Hadoop中HDFS 存储的机制?就和大家介绍到这里。如果想了解更多大数据相关知识,可以持续关注博学谷,或者通过博学谷大数据课程进行学习。我们会持续分享更多关于大数据的知识。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
5分钟掌握Hadoop环境搭建流程
下一篇:
大数据技术自学能学会吗?大数据应该如何自学?
相关推荐 更多

数据库开发转行大数据开发工程师怎么样?
数据库开发转行大数据开发工程师怎么样?大数据的方向的工作有大数据运维工程师、大数据开发工程师、数据分析、数据挖掘、架构师等。有工作经验想转行大数据开发主要考察基础、学习能力、解决问题的能力。
14233
2019-05-20 17:54:38

大数据时代带给我们的重大变革
无论是大数据、人工智能还是区块链都预示着科技的力量会将我们的日常生活带来巨大的变革。就目前而言,大数据已经在很多领域得到了实际的应用。也为我们的生活消费带来的巨大的变革。到2020年,世界上每个人每秒将创造7 MB的数据。下面试10个关于大数据未来预测的问题,告诉你大数据时代带给我们的重大变革。
12285
2019-08-09 18:04:05
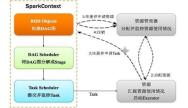
Spark运行架构及其特点讲解
Spark应用程序以进程集合为单位在分布式集群上运行,通过driver程序的main方法创建的SparkContext对象与集群交互。本文主要内容有Spark运行架构的流程讲解和Spark运行架构的特点分析,感兴趣的小伙伴就赶紧看下去吧!
9759
2019-08-20 19:22:54

女生学大数据很累吗?女生适合学大数据吗
女生学大数据很累吗?女生适合学大数据吗?很多人会疑惑女孩子学大数据会不会比男孩子要吃力,其实做大数据没有男女之分,女生做大数据开发也很厉害,只是愿不愿意学没有行不行。 大数据支持很多开发语言,但企业用的最多的还是JAVA,所以有一定Java语言的基础当相于有了基石,可以自己先在电脑上搭建个Hadoop环境练练手。
14347
2019-09-03 10:24:20

大数据智能与人工智能的联系和区别
现在进入了互联网时代,提出人工智能概念,人工智能已经在多个领域中实践,比如无人驾驶、图像识别、语音识别等领域。大数据不断采集、沉淀、分类等积累数据,人工智能基于大数据的支持和采集,运用于人工设定的特定性能和运算方式来实现。
8295
2020-07-27 16:48:30



