在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
分布式系统其实就是为了处理更多数据而存在的。对于大数据学习者来讲,分布式系统入门还是很容易的。本文为大家总结整理了一篇关于分布式系统的学习笔记,主要内容有分布式系统的定义、常用分布式方案以及分布式和集群的对比,下面一起来看看吧~
1、定义
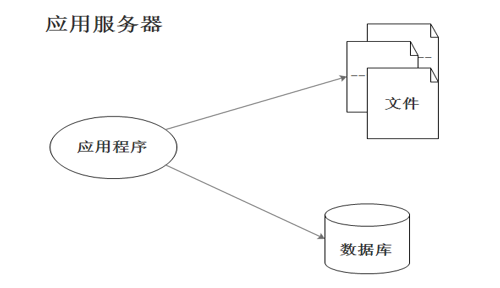
分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。简单来说,就是一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。分布式意味着可以采用更多的普通计算机(相对于昂贵的大型机)组成分布式集群对外提供服务。计算机越多,CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。 初代的web服务网站架构往往比较简单,应用程序、数据库、文件等所有的资源都在一台服务器上。
从分布式系统的定义中我们知道,各个主机之间通信和协调主要通过网络进行,所以,分布式系统中的计算机在空间上几乎没有任何限制,这些计算机可能被放在不同的机柜上,也可能被部署在不同的机房中,还可能在不同的城市中, 对于大型的网站甚至可能分布在不同的国家和地区。
2、常用分布式方案
(1)分布式应用和服务
将应用和服务进行分层和分割,然后将应用和服务模块进行分布式部署。这样做不仅可以提高并发访问能力、减少数据库连接和资源消耗,还能使不同应用复用共同的服务,使业务易于扩展。比如:分布式服务框架 Dubbo。
(2)分布式静态资源
对网站的静态资源如 JS、CSS、图片等资源进行分布式部署可以减轻应用服务器的负载压力,提高访问速度。比如:CDN。
(3)分布式数据和存储
大型网站常常需要处理海量数据,单台计算机往往无法提供足够的内存空间, 可以对这些数据进行分布式存储。比如 Apache HadoopHDFS。
(4)分布式计算
随着计算技术的发展,有些应用需要非常巨大的计算能力才能完成,如果采用集中式计算,需要耗费相当长的时间来完成。分布式计算将该应用分解成许多小的部分,分配给多台计算机进行处理。这样可以节约整体计算时间,大大提高计算效率。比如 Apache HadoopMapReduce。
3、分布式和集群的对比
(1)分布式:是指在多台不同的服务器中部署不同的服务模块,通过远程调用协同工作,对外提供服务。
(2)集群:是指在多台不同的服务器中部署相同应用或服务模块,构成一个集群,通过负载均衡设备对外提供服务。
以上就是分布式系统的学习笔记,大家都看懂了吗?如果觉得本文对你有所帮助,不妨把学习笔记转发出去,让更多的人看到~
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
Hadoop集群动态扩容讲解
下一篇:
在线培训学习大数据怎么样?
相关推荐 更多

实现大数据可视化的十个出发点
实现大数据可视化的十个出发点,需要考虑用户、讲述连贯的故事、迭代设计、个性化一切、从分析目标开始、考虑管理、对观看者的同理心、了解业务、连接可视化、尽可能简化,以便解决手头的假设问题。
12986
2019-04-24 19:16:12

如何搭建hadoop平台?详细步骤讲解
如何搭建hadoop平台?本文将详细讲解以下步骤:虚拟机及系统安装、在虚拟机中配置JAVA环境、修改hosts、修改hostname vim 、配置ssh、压缩包解压、修改hadoop配置文件、修改HBase配置、修改HBase配置、修改hive配置、修改sqoop配置、修改zookeeper配置等等,手把手指导大家搭建hadoop平台。
10914
2019-08-08 15:46:19

大数据技术应用专业有哪些?主要做什么?
大数据概念持续火爆,其核心价值并非仅仅是数据量大,更重要的是在海量的数据背后所体现出来的应用价值。如果把大数据比作一种产业链的话,那么这个产业最终实现价值的关键在于,通过对数据的“加工处理”实现数据的“增值”。因此围绕大数据技术衍生出来大量的应用专业方向。都有哪些大数据技术应用专业呢?他们主要做什么工作呢?下面我们一起来看一下。
14915
2019-09-11 18:29:17

大数据技术的应用领域有哪些?
大数据技术逐渐成熟,已经在诸多领域得到了广泛的应用,随着5G时代的带来,数据化的企业运营成为企业优化产业结构、提升服务质量的奠基。在数据时代数据量迅速扩大、数据维度不断完善、数据分析的指导性更加明显。那大数据技术的应用领域有哪些呢?对于学习大数据技术的同学们而言,应该精准到哪些行业就业呢?
18512
2019-12-16 18:57:00

物联网怎么保护云计算安全?
全球应用的物联网设备已经达到数十亿台,且数量不断增加。在开发和部署的许多物联网设备却缺乏关键的安全功能为黑客和僵尸网络的目标。没有适当的安全措施,物联网设备会导致灾难性事件。如何解决这些问题呢?
7430
2020-03-23 17:51:20



