在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
什么是数据科学异常值检测原理?异常值的检测方法有基于统计的方法,基于聚类的方法,以及一些专门检测异常值的方法等。使用pandas,可以直接使用describe()来观察数据的统计性描述,或者简单使用散点图也能很清晰的观察到异常值的存在。

一、数据科学异常值检测前提
数据样本符合标准正态分布,正态分布的核心是中心极限定理即:如果一个事物受到多种因素的影响,不管每个因素本身是什么分布,它们加总后,结果的平均值就是正态分布。如果要符合正态分布则这些因素必须彼此独立,彼此不独立的各项因素会互相加强影响,那么就构不成正态分布。
二、数据科学异常值检测原理
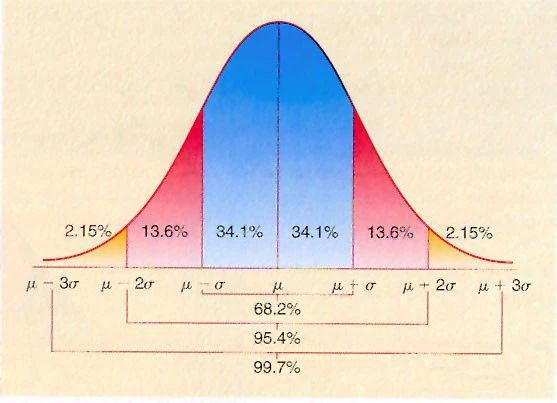
标准正态分布下的曲线为钟型曲线,期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。因此对于一组数据,如果符合正态分布,则可以通过经验法则来检测异常值,同图中可以发现,68.2%的测量值落在μ值处正负一个标准差σ的区间内,95.4%的测量值将落在μ值处正负两个标准差σ的区间内,99.7%的值落在μ值处正负三个标准差σ的区间内。因此,对于一组符合正态分布的数据,如果某个值距离μ值超过三个标准差σ则可以判断这个值属于异常数据。
三、计算步骤
μ值:μ是遵从正态分布的随机变量的均值,由于前提是各种因素对结果的影响为相加,因此μ值的计算可以为样本数据的算术平均值。
标准差σ:所有数据减去其平均值的平方和,所得结果除以该组数之个数N(数据集为总体数据情况,一般用于大数据算法)或者个数N减1(数据集为样本数据情况,认为数据集不是总体数据而是总体数据的一部分,一般用于统计学),再把所得值开根号,所得之数就是这组数据的标准差。
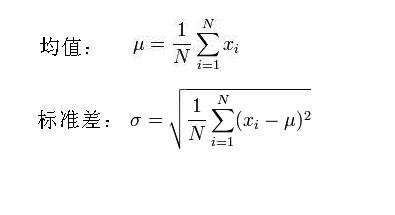 判断逻辑:计算μ+3σ,μ-3σ,当单个数据大于μ+3σ或者小于μ-3σ时,认为此数据为异常值,因为按照经验法则,此数据在数据集的99.7%范围外。
判断逻辑:计算μ+3σ,μ-3σ,当单个数据大于μ+3σ或者小于μ-3σ时,认为此数据为异常值,因为按照经验法则,此数据在数据集的99.7%范围外。
首先理解数据科学异常值检测原理,掌握计算步骤,最终实现对数据科学异常值检测。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
机器学习和数据科学工程师的区别是什么?
下一篇:
常见的数据建模工具有哪些?
相关推荐 更多

大数据对企业的意义是什么?有哪些大数据经典案例?
大数据技术的意义是什么?对于企业而言,可以根据大数据的分析使产品更加符合消费者的需求,根据目标用户特征锁定精准用户群体,同时还可以通过数据制定更好的推广方案,提高有效转化率,也可以帮助企业在危机来临之前展示预警功能,从而降低相应的损失。那有哪些我们知道的大数据经典案例呢?下面我们一起来看一下吧。
11370
2019-07-16 18:21:12

大数据零基础入门书籍推荐
大数据零基础入门书籍推荐,如果你选择的大数据方向不同小编推荐的书籍也不同,下面主要介绍大数据工程师、数据分析师、数据挖掘工程师就业方向的大数据零基础入门书籍,如果你还没确定选什么方向,小编推荐黑马程序员初版的《Hadoop大数据技术原理与应用》比较适合初学者学习。
13691
2019-08-08 15:40:55
Hadoop的联邦机制 大数据学习总结
Hadoop的NN所使用的资源受所在服务的物理限制,不能满足实际生产需求。本文来谈谈大数据学习之Hadoop的联邦机制,主要内容包括:Hadoop的局限与不足、联邦的实现、主要优点、配置和操作。
8552
2019-08-27 20:31:19

深度学习工程师必须掌握的神经网络架构
深度学习工程师必须掌握的神经网络架构,神经网络架构分为四大类:标准网络、递归网络、卷积网络、自动编码器。神经网络可以用来可视化的数据包含两部分:每一层神经元的输出,它们对应输入数据在网络中的不同表示每个神经元所学习到的权重,刻画着各个神经元的行为,即如何对输入进行响应的。
8175
2020-07-01 17:34:28

跳槽直接涨薪25k年薪60w 羡慕的话说麻了
“羡慕”这个词我真的说麻了,之前的薪资25k就已经很高了但是在学完《狂野大数据》课程后找工作直接薪资翻倍
4651
2022-06-07 14:06:39



