在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
现在是大数据的时代,也是数据爆炸的时代,如何处理大数据的存储成为了摆在人们面前的难题,因此分布式文件存储系统应用而生。同时分布式文件存储系统在大数据面试中,也是一个常常可以见到的考点之一。本文为大家梳理了相关的大数据知识点,感兴趣的小伙伴可以看一看。
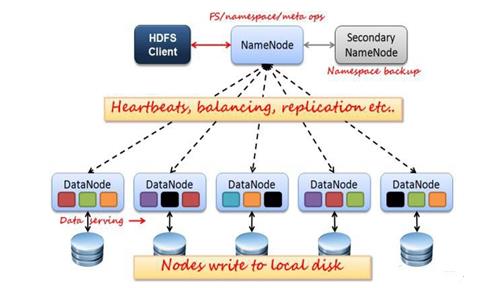
1、架构
如上图所示,HDFS也是按照 Master 和 Slave 的结构。分 NameNode、SecondaryNameNode、DataNode 这几个角色。
NameNode:是 Master 节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理 HDFS 的名称空间;
SecondaryNameNode:是一个小弟,分担大哥 namenode 的一部分工作量;是 NameNode 的冷备份;合并 fsimage 和 fsedits 然后再发给 namenode。
DataNode:Slave 节点,奴隶,干活的。负责存储 client 发来的数据块 block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)namenode 内存中存储的是=fsimage+edits。
SecondaryNameNode负责定时默认1小时,从namenode上,获取 fsimage 和 edits 来进行合并, 然后再发送给 namenode 。减少namenode 的工作量。
2、原理
(1)工作机制
NameNode 负责管理整个文件系统元数据;DataNode 负责管理具体文件数据块存储;Secondary NameNode 协助 NameNod进行元数据的备份。HDFS 的内部工作机制对客户端保持透明,客户端请求访问 HDFS 都是通过向 NameNode 申请来进行。
(2)读写流程
* HDFS 写数据流程
a、 client 发起文件上传请求,通过 RPC 与 NameNode 建立通讯,NameNode 检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
b、 client 请求第一个 block 该传输到哪些 DataNode 服务器上;
c、NameNode 根据配置文件中指定的备份数量及机架感知原理进行文件分配,返回可用的 DataNode 的地址如:A,B,C;注: Hadoop 在设计时考虑到数据的安全与高效,数据文件默认在 HDFS 上存放三份, 存储策略 为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份。
d、client 请求 3 台 DataNode 中的一台 A 上传数据(本质上是一个 RPC调用,建立 pipeline), A 收到请求会继续调用 B,然后 B 调用 C,将整个pipeline 建立完成,后逐级返回 client;
e、 client 开始往 A 上传第一个 block(先从磁盘读取数据放到一个本地内存缓存),以 packet 为单位(默认 64K),A 收到一个 packet 就会传给 B,B 传给 C;A 每传一个 packet 会放入一个应答队列等待应答。
f、数据被分割成一个个 packet 数据包在 pipeline 上依次传输,在 pipeline 反方向上,逐个发送 ack(命令正确应答),最终由 pipeline 中第一个 DataNode 节点 A 将 pipeline ack 发送给 client;
g、 当一个 block 传输完成之后,client 再次请求 NameNode 上传第二个block 到服务器。
*HDFS 读数据流程
a、 Client 向 NameNode 发起 RPC 请求,来确定请求文件 block 所在的位置;
b、 NameNode 会视情况返回文件的部分或者全部 block 列表,对于每个block,NameNode 都会返回含有该 block 副本的 DataNode 地址;
c、 这些返回的 DN 地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的 DN 状态为 STALE,这样的排靠后;
d、 Client 选取排序靠前的 DataNode 来读取 block,如果客户端本身就是DataNode,那么将从本地直接获取数据;
e、 底层上本质是建立 Socket Stream(FSDataInputStream),重复的调用父类 DataInputStream 的 read 方法,直到这个块上的数据读取完毕;
f、 当读完列表的 block 后,若文件读取还没有结束,客户端会继续向NameNode 获取下一批的 block 列表;
g、 读取完一个 block 都会进行 checksum 验证,如果读取 DataNode 时出现错误,客户端会通知 NameNode,然后再从下一个拥有该 block 副本的DataNode 继续读。
h、 read 方法是并行的读取 block 信息,不是一块一块的读取;NameNode 只是返回 Client 请求包含块的DataNode 地址,并不是返回请求块的数据;
i、 最终读取来所有的
3、API
(1)shell 定时采集数据至 HDFS
* 技术分析
HDFS SHELL:
hadoop fs -put // 满足上传 文件,不能满足定时、周期性传入。
Linux crontab: crontab -e
0 0 * * * /shell/ uploadFile2Hdfs.sh //每天凌晨 12:00 执行一次
* 实现流程
一般日志文件生成的逻辑由业务系统决定,比如每小时滚动一次,或者一定大小滚动一次,避免单个日志文件过大不方便操作。比如滚动后的文件命名为 access.log.x,其中 x 为数字。正在进行写的日志文件叫做 access.log。这样的话,如果日志文件后缀是 1\2\3 等数字,则该文件满足需求可以上传,就把该文件移动到准备上传的工作区间目录。工作区间有文件之后,可以使用 hadoop put 命令将文件上传。
以上就是大数据笔记之分布式文件存储系统的知识点梳理,大家有任何不懂的地方,都可以咨询博学谷的在线老师。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
云数据安全之数据加密的要点分析
下一篇:
如何成为一名优秀的云计算架构师?
相关推荐 更多

互联网医疗大数据商业变现应用
互联网医疗大数据商业变现应用,2018年《国家健康医疗大数据标准、安全、服务管理办法(试行)》正式出炉,与以往政策不同,该规定不再停留于宏观指导层面,而是对医疗大数据标准、安全、服务中的权责利进行了详细规定。
9846
2019-04-18 18:12:28

数据库开发转行大数据开发工程师怎么样?
数据库开发转行大数据开发工程师怎么样?大数据的方向的工作有大数据运维工程师、大数据开发工程师、数据分析、数据挖掘、架构师等。有工作经验想转行大数据开发主要考察基础、学习能力、解决问题的能力。
14023
2019-05-20 17:54:38

程序员常用数据库有哪些?
数据库就是数据存储的仓库,任何互联网产品都需要使用数据库保存运营过程中所产生的各种数据。SQL是一种数据库查询语言和程序设计语言,主要就是用于管理数据库中的数据,如存取数据、查询数据、更新数据等。在大数据技术不断提升与应用的市场背景下,数据库技术也得到很大的发展,目前数据库产品非常多,最常用的数据库有:Oracle、DB2、MongoDB、SQLServer、MySQL等。
11823
2019-12-05 18:48:08

大数据技术的应用领域有哪些?
大数据技术逐渐成熟,已经在诸多领域得到了广泛的应用,随着5G时代的带来,数据化的企业运营成为企业优化产业结构、提升服务质量的奠基。在数据时代数据量迅速扩大、数据维度不断完善、数据分析的指导性更加明显。那大数据技术的应用领域有哪些呢?对于学习大数据技术的同学们而言,应该精准到哪些行业就业呢?
18526
2019-12-16 18:57:00

传智教育博学谷狂野大数据课程再传喜讯,学员均薪超2万
近日,传智教育旗下博学谷IT在线教育公开了一组大数据学科的就业薪资数据,即全部学员平均就业薪资为 21775元,平均涨薪额度为8229元,涨幅64.00%;其中,一线城市平均就业薪资24274元,一线城市平均涨薪额度为10080元,涨幅76.91%。
7578
2022-09-29 16:42:09



热门文章
- 前端是什么
- 前端开发的工作职责
- 前端开发需要会什么?先掌握这三大核心关键技术
- 前端开发的工作方向有哪些?
- 简历加分-4步写出HR想要的简历
- 程序员如何突击面试?两大招带你拿下面试官
- 程序员面试技巧
- 架构师的厉害之处竟然是这……
- 架构师书籍推荐
- 懂了这些,才能成为架构师 查看更多
扫描二维码,了解更多信息
