在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
ApacheSpark与 Apache Hadoop数据科学工具有哪些区别?Apache Spark被设计为大规模处理的接口,而 Apache Hadoop 为大数据的分布式存储和处理提供了更广泛的软件框架。两者既可以一起使用也可以作为独立服务使用。Apache Spark 和 Apache Hadoop 都是 Apache 软件基金会提供的流行的开源数据科学工具,由社区开发和支持受欢迎程度和功能不断增长。
1、Apache Spark是什么?
Apache Spark 是一个为高效、大规模数据分析而构建的开源数据处理引擎。Apache Spark 是一个强大的统一分析引擎,数据科学家经常使用它来支持机器学习算法和复杂的数据分析。Apache Spark 可以独立运行,也可以作为 Apache Hadoop 之上的软件包运行。
2、Apache Hadoop是什么?
Apache Hadoop 是一组开源模块和实用程序,旨在简化存储、管理和分析大数据的过程。Apache Hadoop 的模块包括 Hadoop YARN、HadoopMapReduce 和 Hadoop Ozone,但它支持许多可选的数据科学软件包。Apache Hadoop 可以互换使用来指代 Apache Spark 和其他数据科学工具。
3、Apache Spark 与 Apache Hadoop有哪些区别
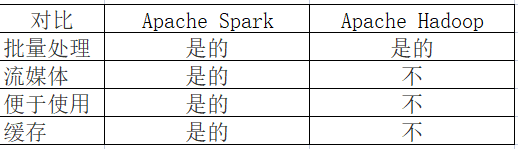
4、设计和架构区别
Apache Spark 是一个离散的开源数据处理实用程序。通过 Spark,开发人员可以访问用于数据处理集群编程的轻量级接口,具有内置的容错和数据并行性。Apache Spark 是用 Scala 编写的,主要用于机器学习应用程序。
Apache Hadoop 是一个更大的框架,其中包括 Apache Spark、Apache Pig、ApacheHive和 Apache Phoenix 等实用程序。作为一种更通用的解决方案,Apache Hadoop 为数据科学家提供了一个完整且强大的软件平台,然后他们可以根据个人需求进行扩展和定制。
5、使用范围
Apache Spark 的范围仅限于它自己的工具,包括 Spark Core、Spark SQL 和 Spark Streaming。Spark Core 提供了 Apache Spark 的大部分数据处理。Spark SQL支持额外的数据抽象层,开发人员可以通过它构建结构化和半结构化数据。Spark Streaming 利用 Spark Core 的调度服务来执行流分析。
Apache Hadoop 的范围要广泛得多。除了 Apache Spark,Apache Hadoop 的开源实用程序还包括pache Phoenix。一个大规模并行的关系数据库引擎。
(1)Apache Zookeeper.。用于云应用程序的协调分布式服务器。
(2)pache Hive。用于数据查询和分析的数据仓库。
(3)Apache Flume。分布式日志数据的仓储解决方案。
但是出于数据科学的目的,并非所有应用程序都如此广泛。速度、延迟和强大的处理能力在大数据处理和分析领域中至关重要——独立安装的 Apache Spark 可能更容易提供这些。
6、速度
对于大多数实现,Apache Spark 将比 Apache Hadoop 快得多。Apache Spark 专为速度而打造,其速度可能比 Apache Hadoop 快近 100 倍。然而,这是因为 Apache Spark 更简单、更轻量级。
默认情况下,Apache Hadoop 不会像 Apache Spark 一样快。但是,其性能可能会因安装的软件包以及所涉及的数据存储、维护和分析工作而异。
7、学习曲线
由于其关注点相对狭窄,Apache Spark 更容易学习。Apache Spark 有一些核心模块,并为数据的操作和分析提供了一个干净、简单的界面。由于 Apache Spark 是一个相当简单的产品,因此学习曲线很短。
Apache Hadoop 要复杂得多。参与的难度将取决于开发人员如何安装和配置 Apache Hadoop 以及开发人员选择包含哪些软件包。无论如何,即使开箱即用,Apache Hadoop 的学习曲线也更为显著。
8、安全性和容错性
当作为独立产品安装时,Apache Spark 的开箱即用安全性和容错功能少于 Apache Hadoop。但是,Apache Spark 可以访问许多与 Apache Hadoop 相同的安全实用程序,例如 Kerberos 身份验证——它们只需要安装和配置即可。
Apache Hadoop 具有更广泛的本机安全模型,并且在设计上具有广泛的容错性。与 Apache Spark 一样,它的安全性可以通过其他 Apache 实用程序进一步提高。
9、编程语言
Apache Spark 支持 Scala、Java、SQL、Python、R、C# 和 F#。它最初是在 Scala 中开发的。Apache Spark 支持数据科学家使用的几乎所有流行语言。
Apache Hadoop 是用 Java 编写的,部分是用 C 编写的。Apache Hadoop 实用程序支持其他语言,使其适合所有技能的数据科学家。
10、在 Apache Spark 与 Hadoop 之间进行选择
如果您是主要从事机器学习算法和大规模数据处理的数据科学家,请选择 Apache Spark。
Apache Spark:
(1)在没有 Apache Hadoop 的情况下作为独立实用程序运行。
(2)提供分布式任务调度、I/O功能和调度。
(3)支持多种语言,包括 Java、Python 和 Scala。
(4)提供隐式数据并行性和容错性。
如果您是需要大量数据科学实用程序来存储和处理大数据的数据科学家,请选择 Apache Hadoop。
Apache Hadoop:
(1)为大数据的存储和处理提供广泛的框架。
(2)提供了一系列令人难以置信的软件包,包括 Apache Spark。
(3)建立在分布式、可扩展和可移植的文件系统之上。
(4)利用其他应用程序进行数据仓库、机器学习和并行处理。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
如何成为高薪的复合型大数据人才?
下一篇:
零基础3天快速入门狂野大数据体验学习
相关推荐 更多

大数据核心技术:Hadoop与spark
大数据学习需要掌握很多技术知识点,包括Linux、Zookeeper、Hadoop、Redis、HDFS、MapReduce、Hive、lmpala、Hue、Oozie、Storm、Kafka、Spark、Scala、SparkSQL、Hbase、Flink、机器学习等。今天主要和大家分享一下Hadoop和spark技术。
9367
2019-06-26 17:59:29

浅析五种编程模型
编程模型,我们可以简单地理解为,它就是模板,遇到相似问题就可以方便依模板解决,这样就简化了编程问题。不同的编程环境和不同的应用对象有不同的编程模型。编程模型也是学习编程内容中的基础知识,小编带着大家来浅析五种编程模型。
10129
2019-08-14 10:32:27

学大数据技术必须了解的大数据经典应用案例
我们已经进入了数据化的时代,大数据开发技术、数据分析已经成为目前企业最核心的关注点。数据为企业提供了更加可靠的支撑,对于优化产业结构、提升生产效率有非常明显的作用。在企业纷纷布局大数据业务的同时,大数据相关人才缺口逐渐扩大。目前国内大数据相关从业人员已经超过20万,作为大数据从业人员,必须了解一些大数据相关的经典应用案例。
8235
2019-08-22 18:03:14

大数据分析专家到大数据技术总监如何转型?
大数据分析专家到大数据技术总监如何转型?大数据分析专家偏重对数据分析的能力,而转型成大数据技术总监除了精通数据分析能力还有具备管理能力,可以带团队做项目。
8714
2019-10-24 15:40:08

为什么大数据技术那么火?
大数据技术的概念早在2008年被Google提出。在我国2012年提出《大数据研究和发展计划》,从此我国的开放、共享和只能的大数据时代正式开启。随着一线互联网企业在大数据领域的成熟应用,以及国内政策的支持。2016年,云计算大数据技术再次成为人们所追捧的热门技术,与此同时国内大数据人才培养体系逐渐完善,为大数据的普及应用提供源源不断的人才支撑。
7569
2020-09-15 17:36:12



