在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
狂野大数据零基础3天快速入门大数据体验学习,本课程除了包含常用的HadoopHive.Hbase, EK. Sqoop. Fume. Karka.Spark 技术和项目,还新增了目前互联网比较流行的Flink. Druid. Kylin等技术和项目。
狂野大数据课程学习并非很困难,想要成为⾼端⼈才努⼒学习是必要的,同时也要有⼀定的学习⽅法去提⾼效率。课上认真听讲课后努⼒练习的⽅式进⾏学习,编程的世界其实很简单,键盘敲烂年薪数⼗万。
课程设计⽬标培养⾼级⼤数据开发⼈才,对标企业5年真实⼤数据从业⼈员的技能⽔平。课程内容由学科中多位⼤数据从业经验丰富的业界⼤⽜设计,知识深度完全覆盖并超出企业开发所需的要求,内容⼴度也覆盖⼤数据⾏业中⼏乎全部常⻅的技术组件和知识点。
课程学习安排路线遵循企业中⼤数据开发者的真实成⻓路径,从分布式⼊⻔Hadoop到Flink计算框架,由浅⼊深,循序渐进,并在学习路线中穿插实战项⽬学习,确保学习效果,分为十个阶段学习:⼤数据的专属操作系统、开源⼤数据框架、千亿级数仓技术、企业级⼤数据数仓平台项⽬实战、PB级内存计算框架、Spark⼤数据项⽬实战、⾼性能NoSQL存储与秒处理百万级消息的顶级MQ、性能之巅——亚秒级实时计算技术、实时⼤数据项⽬实战、⼤⼚⾯试题就业阶段。
那么学完这门课程能收获什么?

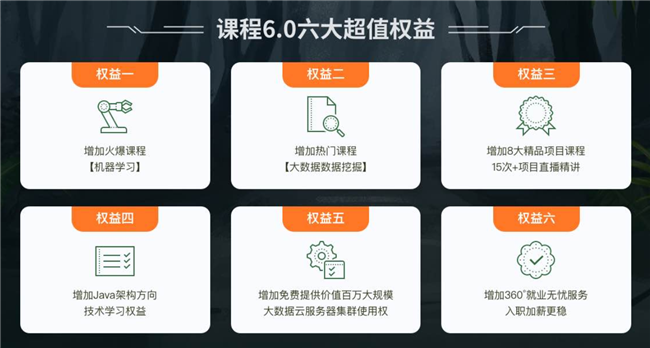
选择狂野大数据能获得哪些课程权益?
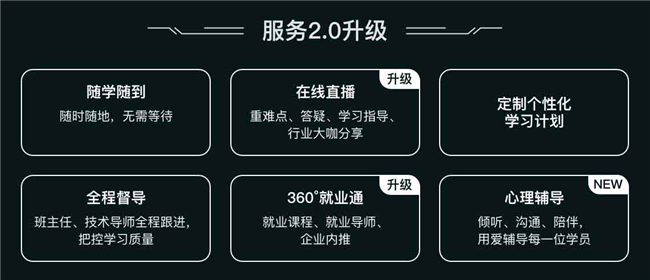
可以享有哪些服务?
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
Apache Spark与 Apache Hadoop数据科学工具有哪些区别?
下一篇:
跳槽直接涨薪25k年薪60w 羡慕的话说麻了
相关推荐 更多

学大数据需要掌握哪些基础?应该如何学习大数据?
学大数据需要掌握哪些基础?应该如何学习大数据?甚至大数据需要掌握哪些知识?大数据已经在通信、IT、金融等领域得到了广泛应用,根据预测,未来3-5年内大数据行业会呈现井喷式的发展。现在入行大数据行业将是一个大的机遇。下面小编与大家分析一下学大数据需要掌握哪些基础以及应该如何学习大数据。
9807
2019-08-08 14:17:52

博学谷云计算大数据培训班课程怎么样?
在线学习已经成为现在年轻人最主要的学习途径。博学谷作为国内高端的IT在线教育平台,依托传智播客13年教学经验的沉淀,推出云计算大数据培训课程。每年都有非常多的小伙伴在博学谷平台学习,对于还在观望的同学,博学谷云计算大数据培训班课程怎么样?在博学谷学习有什么优势呢?
8331
2019-09-06 18:22:40

大数据工程师加班多吗?工作强度大不大?
大数据时代的来临,使得大数据工程师一职也变得火爆起来。许多想要学习大数据并今后投身于此的伙伴,在羡慕这一行广阔发展前景和高额薪资待遇的同时,难免也会担心这样的问题:大数据工程师加班多吗?工作强度大不大?其实我们都明白高薪的工作肯定不轻松的道理,但是大数据工程师的工作强度,也远远没有大家想象的没那么大。而且不同的公司,加班的强度也是不一样的,因此不能一概而论。
16470
2019-12-05 20:33:40

计算机大数据应用技术就业前景怎么样?
计算机大数据应用技术就业前景怎么样?作为目前最为广泛和热门的新兴技术,计算机大数据应用技术的意义不在于存储海量的的数据信息,而在于对这些数据进行专业化处理,从而更好地辅助工作中的各项决策。因此,掌握了计算机大数据应用技术,其就业前景自然广阔明亮无比。关于大数据的更多就业方向选择,我们可以看看以下的具体分析。
15512
2020-01-14 15:33:07

Flink从入门到实践课程介绍
Flink是解放程序员的一款开源大数据计算引擎,本文将为大家介绍Flink从入门到实践的课程详情,主要包括课程的学习内容、亮点特色和学习收获,对Flink感兴趣或者有学习需要的小伙伴可以看一看。
6035
2020-04-21 18:22:10



