在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
HDFS有着高容错性特点,且设计用来部署在低廉的硬件上,提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。HDFS放宽了POSIX的要求,可以实现流的形式访问文件系统中的数据。
Hadoop分布式文件系统HDFS是一种被设计成适合运行在通用硬件上的分布式文件系统。HDFS是一个高度容错性的系统,适合部署在廉价的机器上。它能提供高吞吐量的数据访问非常适合大规模数据集上的应用。
HDFS概念
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机存储文件, 并且提供统一的访问接口。
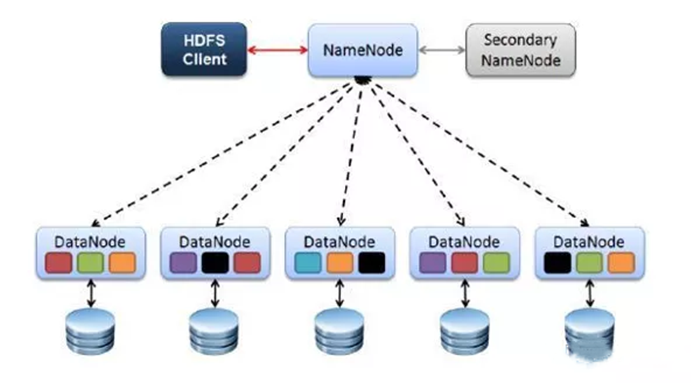
HDFS的四个基本组件:HDFS Client、NameNode、DataNode和Secondary NameNode。
HDFS采用主从结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。
Client
Client是客户端。HDFS Client文件切分。文件上传 HDFS 的时候,Client 将文件切分成 一个一个的Block,然后进行存储。Client 提供一些命令来管理 和访问HDFS,比如启动或者关闭HDFS。
NameNode
NameNode就是 master,它是一个主管、管理者。管理 HDFS 元数据(文件路径,文件的大小,文件的名字,文件权限,文件的block切片信息)。
NameNode管理 Block 副本策略:默认 3 个副本,处理客户端读写请求。
DataNode
DataNode就是Slave。NameNode下达命令,DataNode 执行实际的操作。DataNode存储实际的数据块,执行数据块的读/写操作。定时向namenode汇报block信息。
Secondary NameNode
SecondaryNameNode不是NameNode的备份。当NameNode挂掉的时候,它并不能马上替换NameNode并提供服务。
辅助 NameNode,分担其工作量。在紧急情况下,可辅助恢复 NameNode。
副本机制
HDFS被设计成能够在一个大集群中跨机器可靠地存储超大文件。它将每个文件存储成一系列的数据块,这个数据块被称为block,除了最后一个,所有的数据块都是同样大小的。
为了容错,文件的所有block都会有副本。每个文件的数据块大小和副本系数都是可配置的。
在hadoop2 当中, 文件的 block 块大小默认是 「128M」(134217728字节)。

如图所示,一个大小为300M的a.txt上传到HDFS中,需要进行128M的切分,不足128M分为到另一block中。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
大数据开发培训哪家好?怎么选?
下一篇:
机器学习在线学习网站哪个好?
相关推荐 更多

大数据核心技术:spark学习总结
想要学习大数据,一定要充分掌握大数据的核心技术:Hadoop、Strom、spark等等。Spark是一种与Hadoop像是的开源集群计算环境。它启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
15332
2019-06-19 17:37:43
分布式系统学习笔记
分布式系统其实就是为了处理更多数据而存在的。对于大数据学习者来讲,分布式系统入门还是很容易的。本文为大家总结整理了一篇关于分布式系统的学习笔记,主要内容有分布式系统的定义、常用分布式方案以及分布式和集群的对比,下面一起来看看吧~
7034
2020-06-09 11:12:49

Hadoop集群搭建过程总结
本文主要总结了Hadoop集群搭建的过程,内容包括发行版本说明、Hadoop集群简介、服务器准备、网络环境准备、服务器系统设置以及JDK 环境安装。有学习需要的小伙伴一起来看看吧~
8325
2020-06-18 15:32:40

大数据技术是什么专业?前景如何
大数据技术是什么专业?大数据浪潮下,大数据技术是信息领域的革命,更是在全球领域内加速企业创新,社会变革的技术。大数据能给企业创造商业价值。使用大数据技术解决企业难题难题,灵活、快速、高效地响应瞬息万变的市场需求。
10917
2020-07-17 17:10:55

推荐零基础学习大数据的10本经典图书
学习大数据并不是一蹴而就的事情,及时工作多年的开发工程师都需要不断的补充新鲜的知识内容。目前学习大数据知识可以通过视频和图书两种方式学习,视频的优势在于能够将老师的个人开发经验传授给学习者,而图书的优势在于能够随时翻阅,内容比较丰富。这里为大家推荐零基础学习大数据的8本经典图书,希望同学们能够通过不同的学习途径充分掌握大数据开发技能。
7696
2020-09-14 16:01:31



