在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
今天继续梳理的知识点是HDFS的基本原理,主要内容包括NameNode概述、DataNode概述、HDFS的工作机制(HDFS写数据流程和HDFS读数据流程),总之全文都是总结的学习干货,希望对于相信大数据的朋友能够有一些帮助,下面我们一起来学习并理解以下的内容吧!
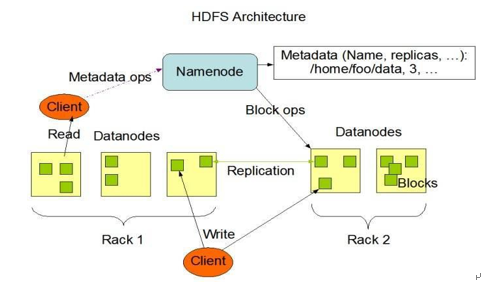
1、NameNode概述
NameNode是HDFS的核心,相信这一点大家都知道,所以NameNode也被称为Master。NameNode仅存储HDFS的元数据:文件系统中所有文件的目录树,并跟踪整个集群中的文件。NameNode不存储实际数据或数据集。数据本身实际存储在DataNodes中。NameNode知道HDFS中任何给定文件的块列表及其位置。使用此信息NameNode知道如何从块中构建文件。NameNode并不持久化存储每个文件中各个块所在的 DataNode 的位置信息,这些信息会在系统启动时从数据节点重建。NameNode对于HDFS至关重要,当NameNode关闭时,HDFS / Hadoop集群无法访问。总结一下,NameNode是Hadoop集群中的单点故障。NameNode所在机器通常会配置有大量内存(RAM)。
2、DataNode概述
DataNode负责将实际数据存储在HDFS中。DataNode也称为Slave。NameNode和DataNode会保持不断通信。DataNode启动时,它将自己发布到NameNode并汇报自己负责持有的块列表。当某个DataNode关闭时,它不会影响数据或群集的可用性。NameNode将安排由其他DataNode管理的块进行副本复制。DataNode所在机器通常配置有大量的硬盘空间。因为实际数据存储DataNode中。DataNode会定期向NameNode发送心跳,如果NameNode长时间没有接受到DataNode发送的心跳, NameNode就会认为该DataNode失效。block汇报时间间隔取参数dfs.blockreport.intervalMsec,参数未配置的话默认为6小时。
3、HDFS的工作机制
NameNode负责管理整个文件系统元数据;DataNode负责管理具体文件数据块存储;Secondary NameNode协助NameNode进行元数据的备份。HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向NameNode申请来进行。HDFS写数据流程和HDFS读数据流程总结如下:
(1)HDFS写数据流程
A.client发起文件上传请求,通过RPC与NameNode建立通讯,NameNode检查目标文件是否已存在,父目录是否存在,返回是否可以上传;
B.client请求第一个block该传输到哪些DataNode服务器上;
C.NameNode根据配置文件中指定的备份数量及副本放置策略进行文件分配,返回可用的DataNode的地址,如:A、B、C;
D.client请求3台DataNode中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将整个pipeline建立完成,后逐级返回client;
E.client开始往A上传第一个block,以packet为单位(默认64K),A收到一个packet就会传给 B,B 传给 C;A 每传一个packet会放入一个应答队列等待应答。
F.数据被分割成一个个packet数据包在pipeline上依次传输,在pipeline反方向上,逐个发送ack(命令正确应答),最终由pipeline中第一个DataNode节点A将pipeline ack发送给client;
G.当一个block传输完成之后,client再次请求NameNode上传第二个block到服务器。
(2)HDFS读数据流程
A、Client 向 NameNode 发起 RPC 请求,来确定请求文件 block 所在的位置;
B.NameNode 会视情况返回文件的部分或者全部block 列表,对于每个block,NameNode 都会返回含有该block副本的DataNode地址;
C.这些返回的DN地址,会按照集群拓扑结构得出 DataNode 与客户端的距离,然后进行排序,排序两个规则:网络拓扑结构中距离 Client 近的排靠前;心跳机制中超时汇报的DN 状态为STALE,这样的排靠后;
D.Client 选取排序靠前的DataNode来读取block,如果客户端本身就是DataNode,那么将从本地直接获取数据;
E.底层上本质是建立Socket Stream(FSDataInputStream),重复的调用父类DataInputStream的read方法,直到这个块上的数据读取完毕;
F.当读完列表的block后,若文件读取还没有结束,客户端会继续向NameNode获取下一批的block列表;
G.读取完一个block都会进行checksum验证,如果读取DataNode时出现错误,客户端会通知 NameNode,然后再从下一个拥有该block副本的DataNode继续读。
H.read 方法是并行的读取block信息,不是一块一块的读取;NameNode只是返回Client 请求包含块的DataNode地址,并不是返回请求块的数据;
I.最终读取来所有的block会合并成一个完整的最终文件。
以上就是HDFS基本原理总结的全部内容了,大家都理解了吗?如果觉得本文总结的干货有用,不妨把文章分享出去,让更多的人看到~
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
ZooKeeper数据模型解析
下一篇:
大数据培训需要什么基础吗?
相关推荐 更多

大数据Lambda架构概念及应用
Lambda Architecture 概念Mathan Marz的大作Big Data: Principles and best practices of scalable real-time data systems介绍了Lambda Architecture的概念,用于在大数据架构中,如何让real-time与batch job更好地结合起来,以达成对大数据的实时处理。
12123
2020-09-04 17:57:48

了解前沿技术:大数据经典应用案例分享
目前国内大部分代行的企业已经将大数据充分的运用到原来的业务之中,对于哪些目前还在互联网转型甚至没有实现互联网+转型的企业来说,能否尽快布局大数据成为企业实现快速发展的核心问题。因此我们需要跟多的了解大数据到底都可以做什么。本文为大家分享了部分大数据应用成功案例。对于企业或者开发者都可以从中找到与自己实际工作业务相关的拓展思路。
12446
2019-07-22 16:28:07

学数据挖掘技术能做哪些工作?可以从事哪些行业?
学数据挖掘技术能做哪些工作?可以从事哪些行业?随着大数据时代的来临,大数据早已渗透我们生活和工作的方方面面。尤其是数据挖掘更是被各行各业广泛应用,像互联网、电商、金融、医疗等等行业对掌握数据挖掘技术的人才更是有着相当优渥的报酬。至于数据挖掘的相关岗位更是选择多多,下面来具体了解一下吧!
12041
2019-10-15 10:29:58

程序员必须掌握的大数据分析核心技术有哪些?
程序员必须掌握的大数据分析核心技术有哪些?大数据分析技术现是一种传统的技术分析模型,主要对数据进行筛选、过滤之后进行分析。随着银行业、保险业,电子商务的不断发展,非结构数据的数量越来越多,增加了大数据分析的难度,对于大数据方面的程序员要求越来越高。
8887
2020-03-05 15:19:17

Hadoop集群动态扩容讲解
今天本文要讲解的是Hadoop集群动态扩容的内容,那么什么是动态扩容呢?数据量随着公司业务的增长越来越大,原有的datanode节点的容量,已经不能满足存储数据的需求,需要在原有集群基础上,动态添加新的数据节点,这就是我们说的动态扩容。下面一起来看看基础准备、添加datanode、datanode负载均衡服务、添加nodemanager等相关内容吧~
8738
2020-06-08 10:56:55



热门文章
- 前端是什么
- 前端开发的工作职责
- 前端开发需要会什么?先掌握这三大核心关键技术
- 前端开发的工作方向有哪些?
- 简历加分-4步写出HR想要的简历
- 程序员如何突击面试?两大招带你拿下面试官
- 程序员面试技巧
- 架构师的厉害之处竟然是这……
- 架构师书籍推荐
- 懂了这些,才能成为架构师 查看更多
扫描二维码,了解更多信息
