在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
Yarn作为一个资源管理、任务调度的框架,其重要性不言而喻。尤其是在近些年的大数据面试中,更是面试题的重点知识之一。为了大家在面试的时候,能够准备的更加充分,小编整理了一份有关分布式资源调度框架Yarn的大数据面试题,内容包括Yarn的架构、工作流程、调度器Scheduler。
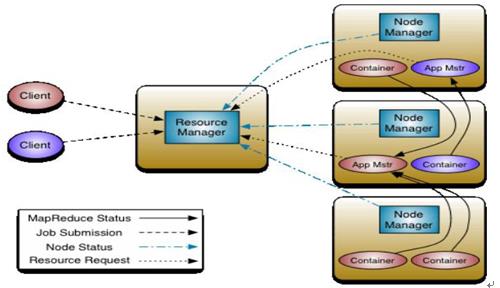
1、Yarn的架构
Yarn是一个资源管理、任务调度的框架, 主要包含三大模块:ResourceManager(RM)、NodeManager(NM)、
ApplicationMaster(AM)。
(1)ResourceManager 负责所有资源的监控、分配和管理;
(2)ApplicationMaster 负责每一个具体应用程序的调度和协调;
(3)NodeManager 负责每一个节点的维护。对于所有的 applications,RM 拥有绝对的控制权和对资源的分配权。而每个 AM 则会和 RM 协商资源,同时和NodeManager 通信来执行和监控 task。
2、Yarn的工作流程
(1)client 向 RM 提交应用程序,其中包括启动该应用的 ApplicationMaster 的必须信息,例如 ApplicationMaster 程序、启动 ApplicationMaster 的命令、用户程序等。
(2)ResourceManager 启动一个 container 用于运行 ApplicationMaster。启动中的 ApplicationMaster 向 ResourceManager 注册自己,启动成功后与 RM 保持心跳。
(3)ApplicationMaster 向 ResourceManager 发送请求, 申请相应数目的container。
(4)ResourceManager 返回 ApplicationMaster 的申请的 containers 信息。申请成功的container,由 ApplicationMaster 进行初始化。container 的启动信息初始化后,AM与对应的 NodeManager 通信,要求 NM 启动 container。AM 与 NM 保持心跳,从而对 NM 上运行的任务进行监控和管理。
(5)container 运行期间,ApplicationMaster 对 container 进行监控。container 通过 RPC协议向对应的 AM 汇报自己的进度和状态等信息。
(6)应用运行期间,client 直接与 AM 通信获取应用的状态、进度更新等信息。
(7)应用运行结束后,ApplicationMaster 向 ResourceManager 注销自己,并允许属于它的 container 被收回。
3、Yarn的调度器Scheduler。
Yarn 中,负责给应用分配资源的就是 Scheduler,三种调度器可以选择: FIFO Scheduler ,Capacity Scheduler,FairScheduler 。
(1)FIFO Scheduler
FIFO Scheduler 把应用按提交的顺序排成一个队列,这是一个 先进先出队列, 在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
(2)Capacity Scheduler
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
(3)Fair Scheduler
在 Fair 调度器中,我们不需要预先占用一定的系统资源,Fair 调度器会为所有运行的 job 动态的调整系统资源。如下图所示,当第一个大 job 提交时, 只有这一个 job 在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair 调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
以上就是关于分布式资源调度框架Yarn的大数据面试题。上面整理的都是重点知识,大家都梳理一遍了吗?还有任何疑问的同学,可以上博学谷咨询线上的老师哦。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
大数据技术应用专业有哪些?主要做什么?
下一篇:
ETL工程师是干什么的?ETL工程师工作内容介绍
相关推荐 更多

大数据Hadoop中HDFS 存储的机制?
HDFS即Hadoop分布式文件系统。它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。那大数据中HDFS 存储的机制怎样的呢?
17527
2019-08-14 10:19:54

盘点五种主流的大数据计算框架
目前市面上有很多大数据框架,如批处理框架Hadoop,流处理框架Storm,以及混合处理型框架Flink和Spark,本文就对当前的分布式计算框架进行了系统的回顾与盘点。
17952
2019-07-02 19:04:03

Namenode HA 知识点讲解
今天,小编准备了今天,小编准备了Namenode HA 知识点讲解,现在分享给大家。
8374
2019-07-04 16:13:08

大数据疑难解答 Hbase内部是什么机制?
众所周知,HBase是一个非关系型数据库,它的特征是分布式、列式存储、开源和版本化。无论是在大数据的面试中,还是大数据的工作中,这都是一个经常会出现的难题,然而却很少人能够说清Hbase内部机制。今天我们就花些时间聊聊Hbase内部是什么机制。
9589
2019-10-17 18:13:28

大数据岗位Spark面试题整理附答案
众所周知,Spark作为一个集群计算平台和内存计算系统,它是专门为速度和通用目标设计的。从事大数据岗位的工作者,像是ETL工程师、Spark工程师、Hbase工程师、用户画像系统工程师都需要熟练掌握Spark相关知识点,因此Spark也是常常会出现的必考面试题。下面我整理了一些Spark面试题,并附上了答案,一起来看看做一做吧!
10290
2020-04-01 17:52:24



