在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
今天本文要讲解的是Hadoop集群动态扩容的内容,那么什么是动态扩容呢?数据量随着公司业务的增长越来越大,原有的datanode节点的容量,已经不能满足存储数据的需求,需要在原有集群基础上,动态添加新的数据节点,这就是我们说的动态扩容。下面一起来看看基础准备、添加datanode、datanode负载均衡服务、添加nodemanager等相关内容吧~

1、基础准备
在基础准备部分,主要是设置 hadoop 运行的系统环境
修改新机器系统 hostname(通过/etc/sysconfig/network 进行修改)
[root@node-4 ~]# cat /etc/sys conf 1g/network
NE TWORKING=yes
HOS TNAME=node -4
[r oot@node-4 ~ ] #
修改 hosts 文件,将集群所有节点 hosts 配置进去(集群所有节点保持hosts文件统一)
rootenode-1 -]# cat /etc/hosts
127.0.0.1 localhost localhost. localdomain localhost4 localhost4. local domain4
: :1 localhost localhost. localdomain localhost6 localhost6. local domain6
192.168.227.151 node-1
192.168.227.152 node-2
192.168.227.153 node-3
192.168.227.154 node-4
rootenode-1 ~]#
设置 NameNode 到 DataNode 的免密码登录(ssh-copy-id 命令实现)
修改主节点 slaves 文件,添加新增节点的 ip 信息(集群重启时配合一键启动脚本使用)
[root@node-1 J]# vim /export/servers/hadoop-2 .6. 0-cdh5.14.0/etc/hadoop/s laves
node-1
node-2
node-3
node-4
在新的机器上上传解压一个新的hadoop安装包,从主节点机器上将hadoop的所有配置文件,scp到新的节点上。
2、添加datanode
在namenode所在的机器的/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop 目录下创建 dfs.hosts 文件
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim dfs.hosts
添加如下主机名称(包含新服役的节点)
node-1
node-2
node-3
node-4
在 namenode 机器的 hdfs-site.xml 配置文件中增加 dfs.hosts 属性
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop vim hdfs-site.xml
<property>
<name>dfs.hosts</name>
<value>/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts</value>
</property>
dfs.hosts 属性的意义:命名一个文件,其中包含允许连接到namenode的主机列表。必须指定文件的完整路径名。如果该值为空,则允许所有主机。相当于一个白名单,也可以不配置。
在新的机器上单独启动datanode:hadoop-daemon.sh start datanode
[root@node-4 ~]# hadoop-daemon.sh start datanode
starting datanode: logging to /export /servers/hadoop-2.6.0-cdh514 .0/ lops /hadoop root datanode -node-4 out
[root@node-4 ~]#
刷新页面就可以看到新的节点加入进来了
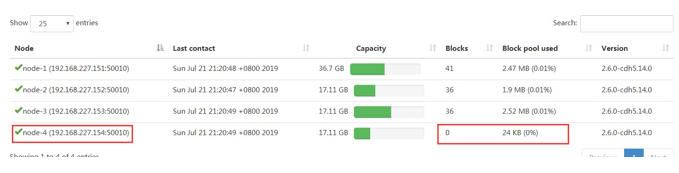
3、datanode负载均衡服务
新加入的节点,没有数据块的存储,使得集群整体来看负载还不均衡。因此最后还需要对hdfs负载设置均衡,因为默认的数据传输带宽比较低,可以设置为64M,即hdfs dfsadmin -setBalancerBandwidth 67108864即可
默认balancer的threshold为10%,即各个节点与集群总的存储使用率相差不超过10%,我们可将其设置为5%。然后启动Balancer,sbin/start-balancer.sh -threshold 5,等待集群自均衡完成即可。
4、添加nodemanager
在新的机器上单独启动 nodemanager:
yarn-daemon.sh start nodemanager
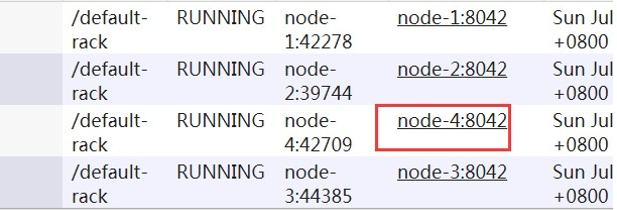
在ResourceManager,通过yarn node -list查看集群情况

以上就是Hadoop集群动态扩容讲解的全部内容,如果你还想更加深入的学习相关内容,可以报名博学谷的大数据课程,在线学习相关视频课程,还有在线讲师一对一为你答疑解惑!
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
HDFS安全模式学习总结
下一篇:
分布式系统学习笔记
相关推荐 更多

大数据Lambda架构概念及应用
Lambda Architecture 概念Mathan Marz的大作Big Data: Principles and best practices of scalable real-time data systems介绍了Lambda Architecture的概念,用于在大数据架构中,如何让real-time与batch job更好地结合起来,以达成对大数据的实时处理。
11853
2020-09-04 17:57:48

大数据应用技术的发展方向分析
如今,大数据的应用对企业公司以及个人都产生了深远影响,本文就来预测一下大数据应用技术的发展方向。可以预见的是,数据资产管理、数据资产管理、AI驱动的数据基础设施、面向AI的分布式计算框架和数据安全这些都将成为大数据应用技术的发展方向。对大数据应用技术感兴趣的小伙伴,可以接着往下看小编的的详细分析。
8634
2019-10-29 17:24:18

常用的数据分析方法及案例讲解
常用的数据分析方法有描述统计、信度分析、相关分析、回归分析、聚类分析等。本文将结合实际案例,为大家一一讲解这些数据分析的方法。如果你想了解如何做数据分析,就接着看下去吧~
7595
2020-08-13 16:38:58

为什么大数据技术那么火?
大数据技术的概念早在2008年被Google提出。在我国2012年提出《大数据研究和发展计划》,从此我国的开放、共享和只能的大数据时代正式开启。随着一线互联网企业在大数据领域的成熟应用,以及国内政策的支持。2016年,云计算大数据技术再次成为人们所追捧的热门技术,与此同时国内大数据人才培养体系逐渐完善,为大数据的普及应用提供源源不断的人才支撑。
7303
2020-09-15 17:36:12

Apache Spark与 Apache Hadoop数据科学工具有哪些区别?
Apache Spark被设计为大规模处理的接口,而 Apache Hadoop 为大数据的分布式存储和处理提供了更广泛的软件框架。两者既可以一起使用也可以作为独立服务使用。Apache Spark 和 Apache Hadoop 都是 Apache 软件基金会提供的流行的开源数据科学工具,由社区开发和支持受欢迎程度和功能不断增长。
4669
2022-06-02 11:25:53



