在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
Hive是建立在Hadoop上的数据仓库基础构架。对于有一定基础的大数据学习者来讲,Hive是必须掌握的核心技术。本文主要带大家来认识一下Hive,了解什么是Hive?为什么要用Hive?如果大家对这些问题好奇,就一起看看接下来的内容吧~

1、什么是Hive?
(1)Hive的定义
Hive一个可以将结构化的数据文件映射为一张数据库表并提供类SQL查询功能的数据仓库工具,而且它是基于Hadoop的。因此,从本质上来看,Hive是将SQL转换为MapReduce程序的工具。因为,比直接用MapReduce开发效率更高,Hive的主要作用就是用来做离线数据分析。
(2)Hive架构
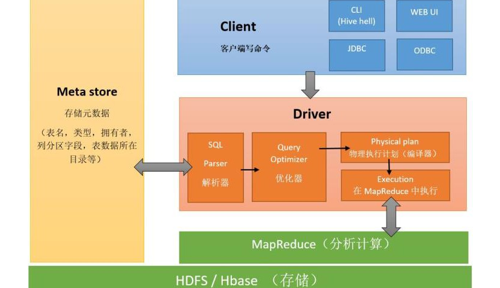
用户接口:包括 CLI 、JDBC/ODBC 、WebGUI 。其中, CLI(command line interface)为 shell 命令行;JDBC/ODBC 是 Hive 的 JAVA 实现,与传统数据库JDBC 类似;WebGUI 是通过浏览器访问 Hive。
元数据存储:通常是存储在关系数据库如 mysql/derby 中。Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器:完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS中,并在随后有 MapReduce 调用执行。
(3)Hive数据模型
Hive中所有的数据都存储在HDFS中,没有专门的数据存储格式。在创建表时指定数据中的分隔符,Hive就可以映射成功,解析数据。Hive中包含以下数据模型:
db:在hdfs中表现为hive.metastore.warehouse.dir目录下一个文件夹;
table:在hdfs中表现所属db目录下一个文件夹;
external table:数据存放位置可以在 HDFS 任意指定路径;
partition:在hdfs中表现为table目录下的子目录;
bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件。
2、为什么要用Hive?
(1)Hive与传统数据库对比
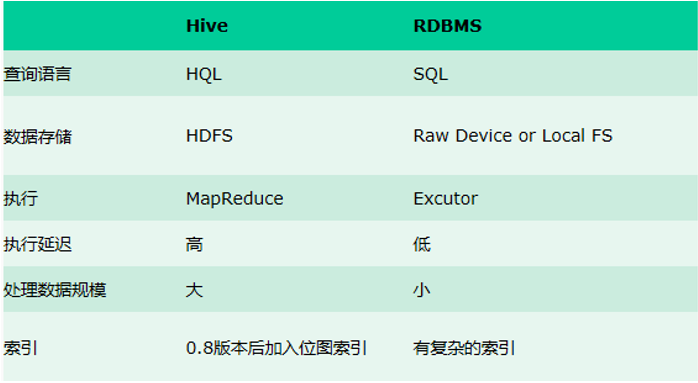
Hive用于海量数据的离线数据分析。Hive具有sql数据库的外表,但应用场景完全不同,Hive只适合用来做批量数据统计分析。
(2)Hive的优势
Hive利用HDFS存储数据,利用MapReduce查询分析数据。因为直接使用Hadoop MapReduce处理数据,会面临人员学习成本太高的问题,而且MapReduce实现复杂查询逻辑开发难度太大。而使用Hive,操作接口采用类SQL语法,提供快速开发的能力的同时还避免了去写MapReduce,从而减少开发人员的学习成本,功能扩展更加方便。
看到这里,想必大家对于“什么是Hive?为什么要用Hive?”,已经有了一定的了解。如果大家想要更加深入的学习大数据中的核心技术Hive,可以在下方申请免费试学名额,获取免费的大数据在线学习机会~
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
什么是数据库?用来做什么?
下一篇:
数据仓库是什么?基本概念讲解
相关推荐 更多

大数据开发工程师需要了解的热门技术
目前大数据、人工智能、区块链已经成为未来互联网核心的发展趋势。人工智能技术还未成熟,而区块链的落地应用也缺乏市场的支撑,而大数据技术已经逐渐融入到各行各业,对于大数据开发工程师而言,哪些技术是受欢迎的?应该注重哪些方面技术的学习?
8113
2019-12-10 18:47:11
用户画像在电商中的价值和作用分析
在了解用户画像在电商行业的应用之前,我们首先要清楚什么是用户画像。简单来说,用户画像就是把用户的信息进行标签化,从而提供给企业和公司。在当下这个大数据时代,各个企业公司早就把用户画像,作为重要的经营战略调整依据。因此,用户画像在电商中的价值和作用不言而喻。下面就为大家着重讲讲用户画像的定义、作用和价值。
11957
2019-12-16 17:11:05

云计算、AI大数据技术在智慧交通方面的应用
云计算、AI大数据技术在智慧交通方面的应用,缓解拥堵,智能信号控制系统及时调整信号时长;加强监控范围有效查处违章行为,打击违法车辆降低交通事故发生;协同指挥防止后续交通堵塞;对路况及时发布,引导司乘人员错开高峰路段就近调整路线等。
11842
2020-02-21 10:34:00

什么是数据库?用来做什么?
什么是数据库?用来做什么?我们在编程和网络经常会听到数据可这个词,作为市场调研和用户分析的重要工具,那么究竟什么是数据库?数据库是存放数据的仓库。它的存储空间很大,可以存放百万条、千万条、上亿条数据。但是数据库并不是随意地将数据进行存放,是有一定的规则的,否则查询的效率会很低。
6668
2020-06-03 14:16:12

元数据是什么?它有什么用?
在大家接触到数据仓库管理系统的学习之后,有一个绕不开的知识点就是元数据。那么,元数据是什么?它有什么用呢?简单来讲,元数据就是描述数据的数据,它的作用就是维护数据仓库。如果大家还不明白,可以看看下面更加具体的解释~
9576
2020-06-05 15:36:25



热门文章
- 前端是什么
- 前端开发的工作职责
- 前端开发需要会什么?先掌握这三大核心关键技术
- 前端开发的工作方向有哪些?
- 简历加分-4步写出HR想要的简历
- 程序员如何突击面试?两大招带你拿下面试官
- 程序员面试技巧
- 架构师的厉害之处竟然是这……
- 架构师书籍推荐
- 懂了这些,才能成为架构师 查看更多
扫描二维码,了解更多信息
