在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
累加器和广播变量分别在什么场景使用?累加器分布式共享只写变量,如果在转换算子中调用累加器后续没有行动算子,累加器不会执行。后续如果调用了两次行动算子,会执行两次累加器出现多加的情况。
1、广播变量的使用方法介绍
解决的场景:
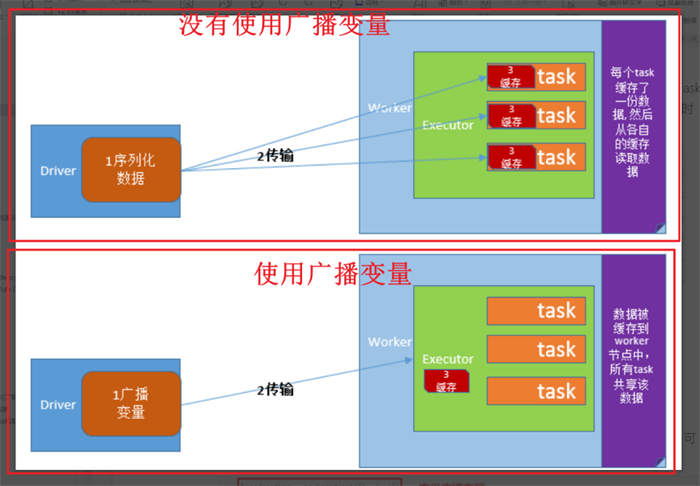
将Driver进程的共享数据发送给所有子节点Executor进程的每个任务中。如果不用广播变量技术,那么Driver端默认会将共享数据分发到每个【Task】中,造成网络分发压力大。
如果使用了广播变量技术,则Driver端将共享数据只会发送到每【Executor】一份。Executor中的所有【Task】都复用这个对象。要保证该共享对象是可【序列化】的。因为跨节点传输的数据都要是可序列化的。
在Driver端将共享对象广播到每个Executor:
val bc = sc.broadcast( 共享对象 )
在Executor中获取:
bc.value
2、累加器的使用方法介绍
集群中所有Executor对同一个变量进行累计操作。Spark目前只支持累【加】操作。有3种内置的累加器:【LongAccumulator】、【DoubleAccumulator】、【CollectionAccumulator】。
整数累加器使用方法
在Driver端定义整数累加器,赋初始值。
acc=sc.accumulator(0)
在Executor端每次累加1
acc+=1
或者acc.add(1)
3、综合案例
# -*- coding:utf-8 -*-
# Desc:This is Code Desc
from pyspark import SparkConf, SparkContext
import os
os.environ['SPARK_HOME'] = '/export/server/spark'
PYSPARK_PYTHON = "/root/anaconda3/bin/python3.8"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
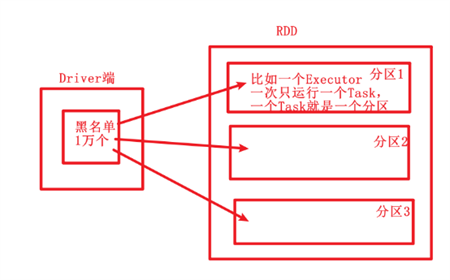
#需求1:从大量用户中,剔除掉黑名单用户
conf=SparkConf().setAppName('sharevalue_review')\
.setMaster('local[*]')
sc=SparkContext(conf=conf)
sc.setLogLevel('WARN')
#创建大量用户
rdd_all=sc.parallelize(['zs','ls','ww','zl'])
#创建黑名单用户
black_list=['zs','ls']
#定义广播变量
bc=sc.broadcast(black_list)
#从大量用户中剔除掉黑名单用户
def filter_black(str):
#获取广播变量
black_list2=bc.value
if str in black_list2:
return False
else:
return True
filterd_rdd=rdd_all.filter(filter_black)
print('过滤后:')
print(filterd_rdd.collect())
#需求2:从大量数字中,挑选出带有7的数字,并计算他们的平均值。
#定义大量数字
rdd_all2=sc.parallelize(range(1,1001))
#定义累加器
#定义累加器1 ,记录有多少个7
acc = sc.accumulator(0)
#定义累加器2 ,将带有7的数字加起来
acc2=sc.accumulator(0)
def find7(i):
global acc
global acc2
if '7' in str(i):
acc+=1
acc2+=i
rdd2=rdd_all2.map(find7)
rdd2.count()
num_7=acc.value
sum_7=acc2.value
avg_7=sum_7/num_7
print('带有7数字的个数是',num_7,'他们的平均数是',avg_7)
小伙伴们一定要自己亲手敲代码进行练习,以上代码不仅练习了累加器和广播变量如何使用,还涉及了函数式编程(Map、Filter)如何使用,上下文变量如何创建、如何用并行化集合的方式创建RDD等,这些练习比较综合,希望可以帮助大家学到更多的技能。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
大数据spark框架常用数据类型RDD与DataFrame的区别
下一篇:
大数据的核心价值是什么? 本质是什么?
相关推荐 更多

什么是大数据即时分析?对金融服务的意义?
什么是大数据即时分析?对金融服务的意义?当今的金融服务公司正在寻求通过利用大数据分析来竞争,在数据战略方面获胜的结构:管理:数据迁移、数据选择、数据存储、数据测试;分析:数据结构、数据分析、机器学习、数据可视化;成果:成功指标、业务决策、货币化、市场领导力。
13750
2019-05-14 16:39:50

大数据Hadoop中HDFS 存储的机制?
HDFS即Hadoop分布式文件系统。它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。那大数据中HDFS 存储的机制怎样的呢?
18060
2019-08-14 10:19:54

零基础参加大数据培训就业前景好不好?
零基础参加大数据培训就业前景好不好?回答这个问题不能一概而论,要具体问题具体分析。就目前的大数据就业形势分析,大数据人才的缺口是相当大的。当然大数据并不是一个低门槛的技术岗位,因此一些零基础想要转行的朋友就必须通过系统正规的培训,在熟练掌握大数据核心技术的基础上,才能在竞争日渐激烈的就业市场中脱颖而出。因此,参加一个靠谱的培训课程的重要性毋庸置疑。
7925
2020-01-03 15:32:59

大数据岗位基础要求有哪些?
大数据岗位基础要求:谈起大数据,当然少不了分析软件,这应该是做大数据工作的基础,但市场上有很多各种各样的分析软件,如果没有过人的经验,真的很难找到适合自己或者适合企业的。笔者通过各大企业对大数据相关行业的职位要求,归纳出如下要点:
7646
2020-07-06 14:22:39

大数据自学要多久?为什么零基础自学大数据那么久?
伴随着大数据时代的冲击,大数据开发相关的技术人才成为目前招聘市场炙手可热的高薪岗位,越来越多想要通过技术获得高薪工作的同学选择大数据技术方向。我们知道目前学习大数据可以通过自学或者参加培训两种方式,参加大数据培训一般5-6个月就可以掌握大数据技术,那自学大数据的话要多久呢?
9543
2020-09-14 15:56:48



