在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
Pandas如何分块处理大文件?在处理快手的用户数据时,碰到600M的txt文本,用sublime打开蹦了,用pandas.read_table()去读竟然花了小2分钟,打开有3千万行数据。仅仅是打开,要处理的话不知得多费劲。
解决:读取文件的函数有两个参数:chunksize、iterator。原理分多次不一次性把文件数据读入内存中。
1.指定chunksize分块读取文件
read_csv 和 read_table 有一个 chunksize 参数,用以指定一个块大小(每次读取多少行),返回一个可迭代的 TextFileReader 对象。
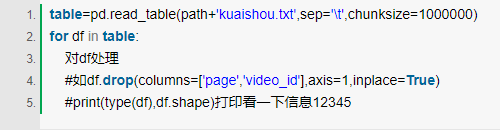
对文件进行了划分,分成若干个子文件分别处理(to_csv也同样有chunksize参数)
2.指定iterator=True

直接看pandas文档相关的内容。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
数据可视化常用工具推荐
下一篇:
零基础能学大数据技术吗?学完能找到工作吗?
相关推荐 更多

什么是大数据即时分析?对金融服务的意义?
什么是大数据即时分析?对金融服务的意义?当今的金融服务公司正在寻求通过利用大数据分析来竞争,在数据战略方面获胜的结构:管理:数据迁移、数据选择、数据存储、数据测试;分析:数据结构、数据分析、机器学习、数据可视化;成果:成功指标、业务决策、货币化、市场领导力。
13769
2019-05-14 16:39:50

大数据Kafka进阶面试题汇总
Kafka是一个分布式、支持分区的、多副本的,基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景。在大数据面试中,Kafka也是一个必考点。因此小编汇总了历年来比较经典常见的大数据Kafka进阶面试题。
7895
2019-08-22 19:26:09
什么是数据可视化?三分钟快速解读
大数据时代如何做好数据分析是每个企业都在关注的问题,而数据可视化无疑是未来的发展趋势之一。相信大家对数据可视化并不陌生,但是大家真的了解什么是数据可视化吗?本文就用三分钟简单解读一下数据可视化的概念、发展、优势和工具,带大家快速了解和认识数据可视化。
10895
2019-11-29 16:51:22

HDFS基本操作学习总结
本文为大家总结了关于HDFS基本操作的学习笔记,具体内容包括Shell命令行客户端、Shell命令选项和Shell常用命令介绍。全文干货建议大家收藏起来,在学习和工作中慢慢进行记忆和查询~
9185
2020-06-10 10:56:20

做数据分析为什么梳理标签体系很重要?
做数据分析为什么梳理标签体系很重要?在提升能力是要先会打一个标签再掌握整个体系。围绕某个业务实现业务闭环操作的若干个标签组合,称为标签体系,单一的标签没办法满足闭环操作的需求,因此需要标签体系。
6208
2022-03-29 14:45:43



