在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
作为一名合格的运营,很多时候需要掌握数据分析能力。⽐如你新进到⼀家公司做新媒体内容编辑,那你需要盘点公司已有的内容资产,避免重复⽣产内容。这时候就需要把⽹页上的数据给扒下来,放在⼀起才会⼀⽬了然。从⽹页上爬取数据,最好⽤的⽅法当然是爬⾍⼯具啦~本文将为手把手教大家如何使用Web Scraper爬取数据,帮助运营小白快速上手爬虫工具!

第一步:下载 Web Scraper
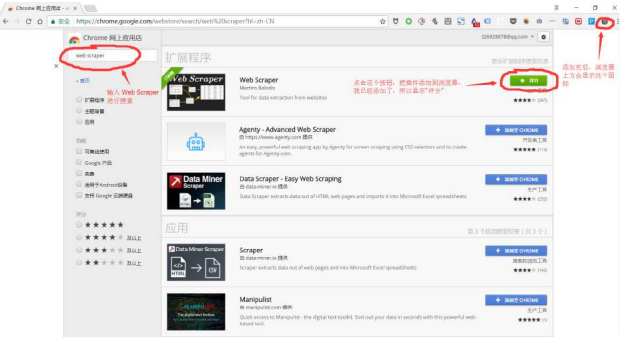
Web Scraper是Chrome浏览器上的⼀个插件,你需要翻墙进⼊Chrome应⽤商店,下载Web Scraper插件。
第二步:打开Web Scraper
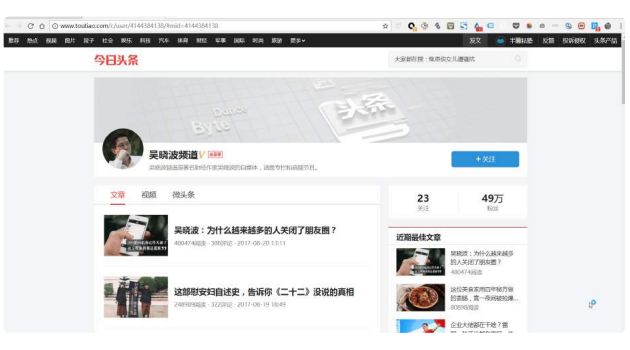
先打开⼀个你想爬数据的⽹页,⽐如我想爬今⽇头条上「吴晓波频道」这个账户的⽂章标题、时间、 评论数,那我就先打开它,再⼀⼀进⾏操作。然后⽤快捷键 Ctrl + Shift + I / F12 打开 Web Scraper。
第三步:新建⼀个 Sitemap
点击Create New Sitemap,⾥⾯有两个选项,import sitemap是指导⼊⼀个现成的sitemap,运营⼩⽩⼀般没有现成的,所以⼀般不选这个,选create sitemap就好。然后进⾏这两个操作:
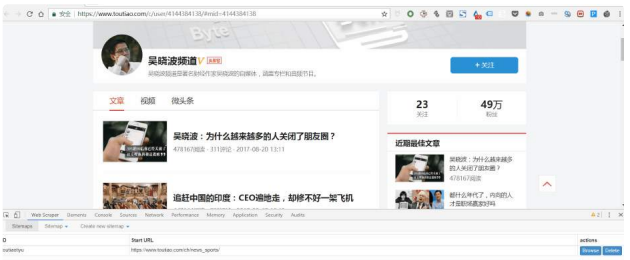
Sitemap Name:代表你这个Sitemap是适⽤于哪⼀个⽹页的,所以你可以根据⽹页来⾃命名,不过需要使⽤英⽂字母,⽐如我抓的是今⽇头条的数据,那我就⽤toutiao来命名;Sitemap URL:把⽹页链接复制到Star URL这⼀栏,⽐如图⽚⾥我把「吴晓波频道」的主页链接复制到了这⼀栏。
第四步:设置这个Sitemap
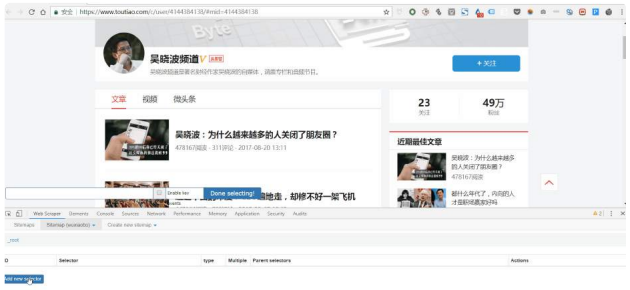
整个Web Scraper的抓取逻辑是这样:设置⼀级Selector,选定定抓取范围;在⼀级Selector 下设置⼆级Selector,选定抓取字段,然后抓取。
再举个例⼦,假如你要获取福建⼈的姓名、性别和年龄这三个要素,那么你得这么做:⾸先要定位到福建省,然后再在福建省⾥⾯去定位姓名、性别、年龄。在这⾥,⼀级Selector表⽰你要在中国这个⼤的国家圈出福建省,⼆级Selector 表⽰你要在福建省的⼈⼜中圈定姓名、性别、年龄这三个要素。对于⽂章⽽⾔,⼀级Selector就是你要把这⼀块⽂章的要素圈出来,这个要素可能包含了标题、作者、发布时间、评论数等等,然后我们再在⼆级Selector 中挑出我们要的要素,⽐如标题、作者、阅读数。
(1)点击Add new selector创建⼀级Selector,按照以下步骤操作:
a.输⼊id : id代表你抓取的整个范围,⽐如这⾥是⽂章,我们可以命名为 126 wuxiaobo-articles;
b.选择 Type : type 代表你抓取的这部分的类型,⽐如元素/⽂本/链接,因为这个是整个⽂章要素范围选取,我们需要⽤Element来先整体选取(如果这个⽹页需要滑动加载更多,那就选Element Scroll Down);
c.勾选Multiple :勾选 Multiple 前⾯的⼩框,因为你要选的是多个元素⽽不是单个元素,当我们勾选的时候,爬⾍插件会帮助我们识别多篇同类的⽂章;
d.保留设置:其余未提及部分保留默认设置。
(2)点击select选择范围,按照以下步骤操作:
a.选择范围:⽤⿏标选择你要爬取数据的范围,绿⾊是待选区域,⽤⿏标点击后变为红⾊,才是选中了这块区域;
b.多选:不要只选⼀个,下⾯的也要选,否则爬出来的数据也只有⼀⾏;
c.完成选择: 记得点Done Selecting;
d.保存:点击Save Selector。
(3)设置好了这个⼀级的Selector之后,点进去设置⼆级的Selector,按照以下步骤操作:
a.新建Selector:点击Add new selector ;
b.输⼊id :id代表你抓取的是哪个字段,所以可以取该字段的英⽂,⽐如我要选「作者」,我就写「writer」;
c.选择Type:选Text ,因为你要抓取的是⽂本;
d.勿勾选Multiple:不要勾选Multiple前⾯的⼩框,因为我们在这⾥要抓取的是单个元素; 保留设置:其余未提及部分保留默认设置。
(4)点击select,再点击你要爬取的字段,按照以下步骤作:
a.选择字段:这⾥爬取的字段是单个的,⽤⿏标点击该字段即可选定,⽐如要爬标题,那就⽤⿏标点击某篇⽂章的标题,当字段所在区域变红即为选中;
c.完成选择:记得点 Done Selecting ;
d.保存:点击 Save Selector 。
(5)重复以上操作,指导选完你想爬去的字段。
第五步:爬取数据
之所以说Web Scraper是运营小白必会的爬⾍⼯具,就是因为只需要设置完所有的Selector,就可以开始爬数据了,怎么样是不是很简单?那么怎么开始爬数据呢?只需要⼀个简单的操作:点击 Scrape ,然后点 Start Scraping , 会弹出⼀个⼩窗,然后⾟勤的⼩爬⾍就开始⼯作了。你会得到⼀个列表,上⾯有你想要的所有数据。
以上就是运营小白必会的爬虫工具使用教程,怎么样,你是不是已经快速上⼿Web Scraper的所有操作过程了?相信即使是不会编程语言的小白,也可以掌握在5分钟之内爬取数据的爬虫工具!
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
流量比较多的五大自媒体平台盘点
下一篇:
老带新营销方式的核心逻辑解析
相关推荐 更多

新媒体运营怎样开展工作?怎样做好新媒体运营?
随着智能手机和通讯技术的发展,出现了崭新的媒体形态,由此新媒体运营也成为了热门职业之一。这个行业的入门门槛比较低,只要会编辑文章、会排版,似乎就可以胜任新媒体运营的工作了。其实不然,要做好新媒体运营,要考虑到方方面面。那么新媒体运营怎样开展工作?怎样做好新媒体运营?
7823
2019-09-17 10:00:45

新媒体短视频运营难吗?什么人适合这个工作?
因为微信公众号和自媒体的出现,国内掀起新媒体运营的浪潮,又因为抖音快手的快速传播,让短视频运营成为备受关注的岗位。那新媒体短视频运营难吗?什么人适合做这份工作?
10740
2019-10-25 17:59:17

如何做好营销推广?内容和渠道是核心
在当下这个互联网快速发展的时代,挑战和机遇并存,能否做好营销推广成为企业经营的重要一环。那么如何才能做好营销推广呢?探求其本质,营销推广的核心不外乎就是内容和渠道。只要做好这两点,营销推广的效果自然不必多说。下面我们来看看内容和渠道到底要怎么做。
9272
2019-11-15 11:44:57

用户运营到底在运营什么?
用户运营是什么?用户运营到底在运营什么?在互联网领域,无论是流量赛道还是产品赛道,运营的核心始终在用户身上。契合传统行业中的“顾客就是上帝”这句话。没有用户的产品,无法实现最终的业务逻辑和盈利,只要有了足够庞大的用户基数,及时产品略有漏洞,也可以获得不错的收益。在运营岗位中专门有一个岗位是用户运营,就是以用户为核心的运营策略策划与执行者。
6474
2019-11-21 18:45:28
裂变引流有哪些方式?四种玩法大揭秘
在网络营销的世界里,裂变不得不说是一个十分有效的引流方式。尤其是在流量成本越来越高的当下,裂变以其成本低、效果好和影响力大的显著优点,所备受运营者的推崇。那么,裂变引流有哪些方式呢?大致归纳起来有社群裂变、分销裂变、红包裂变和H5裂变四种玩法,下面我们来看看这些裂变方式的常规玩法。
14162
2020-03-05 18:16:55



