在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
SparkSQL 结构化数据处理流程及原理是什么?Spark SQL 可以使用现有的Hive元存储、SerDes 和 UDF。它可以使用 JDBC/ODBC 连接到现有的 BI 工具。有了 Spark SQL,用户可以编写 SQL 风格的查询。
Spark SQL 是 Spark 生态系统中处理结构化格式数据的模块。它在内部使用 Spark Core API 进行处理,但对用户的使用进行了抽象。这篇文章深入浅出地告诉你 Spark SQL 3.x 的新内容。
这对于精通结构化查询语言或 SQL 的广大用户群体来说,基本上是很有帮助的。用户也将能够在结构化数据上编写交互式和临时性的查询。Spark SQL 弥补了弹性分布式数据集RDD和关系表之间的差距。RDD 是 Spark 的基本数据结构。它将数据作为分布式对象存储在适合并行处理的节点集群中。RDD 很适合底层处理,但在运行时很难调试,程序员不能自动推断模式schema。另外,RDD 没有内置的优化功能。Spark SQL 提供了数据帧DataFrame和数据集来解决这些问题。
Spark SQL 可以使用现有的 Hive 元存储、SerDes 和 UDF。它可以使用 JDBC/ODBC 连接到现有的 BI 工具。
数据源
大数据处理通常需要处理不同的文件类型和数据源(关系型和非关系型)的能力。Spark SQL 支持一个统一的数据帧接口来处理不同类型的源,如下所示。
文件:
CSV
Text
JSON
XML
JDBC/ODBC:
Postgres
带模式的文件:
AVRO
Parquet
Hive 表:
Spark SQL 也支持读写存储在 Apache Hive 中的数据。
通过数据帧,用户可以无缝地读取这些多样化的数据源,并对其进行转换/连接。
Spark SQL 3.x 的新内容
在以前的版本中(Spark 2.x),查询计划是基于启发式规则和成本估算的。从解析到逻辑和物理查询计划,最后到优化的过程是连续的。这些版本对转换和行动的运行时特性几乎没有可见性。因此,由于以下原因,查询计划是次优的:
1、缺失和过时的统计数据
2、次优的启发式方法
3、错误的成本估计
Spark 3.x 通过使用运行时数据来迭代改进查询计划和优化,增强了这个过程。前一阶段的运行时统计数据被用来优化后续阶段的查询计划。这里有一个反馈回路,有助于重新规划和重新优化执行计划。
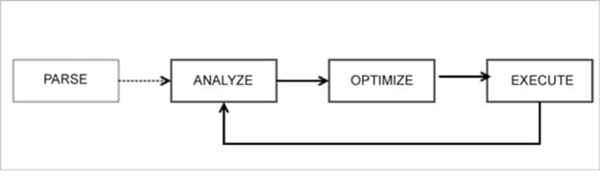
自适应查询执行(AQE)
查询被改变为逻辑计划,最后变成物理计划。这里的概念是“重新优化”。它利用前一阶段的可用数据,为后续阶段重新优化。正因为如此,整个查询的执行要快得多。
动态合并“洗牌”分区
Spark 在“洗牌shuffle”操作后确定最佳的分区数量。在 AQE 中,Spark 使用默认的分区数,即 200 个。这可以通过配置来启用。
动态切换连接策略
广播哈希是最好的连接操作。如果其中一个数据集很小,Spark 可以动态地切换到广播连接,而不是在网络上“洗牌”大量的数据。
动态优化倾斜连接
如果数据分布不均匀,数据会出现倾斜,会有一些大的分区。这些分区占用了大量的时间。Spark 3.x 通过将大分区分割成多个小分区来进行优化。
其他改进措施
此外,Spark SQL 3.x还支持以下内容。
动态分区修剪
3.x 将只读取基于其中一个表的值的相关分区。这消除了解析大表的需要。
连接提示
如果用户对数据有了解,这允许用户指定要使用的连接策略。这增强了查询的执行过程。
兼容 ANSI SQL
在兼容 Hive 的早期版本的 Spark 中,我们可以在查询中使用某些关键词,这样做是完全可行的。然而,这在 Spark SQL 3 中是不允许的,因为它有完整的 ANSI SQL 支持。例如,“将字符串转换为整数”会在运行时产生异常。它还支持保留关键字。
较新的 Hadoop、Java 和 Scala 版本
从 Spark 3.0 开始,支持 Java 11 和 Scala 2.12。 Java 11 具有更好的原生协调和垃圾校正,从而带来更好的性能。 Scala 2.12 利用了 Java 8 的新特性,优于 2.11。
Spark 3.x 提供了这些现成的有用功能,而无需开发人员操心。这将显着提高 Spark 的整体性能。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
大数据在医疗领域应用有哪些挑战?
下一篇:
如何成为高薪的复合型大数据人才?
相关推荐 更多

大数据工程师干不过35岁?大数据职业发展前景如何?
大数据工程师干不过35吗?事实上,大数据工程师现在十分吃香,而且工作经验越高越抢手,不存在“干不过35岁”的说法。如果大家真的掌握了大数据技术,其职业发展前景是完全不用担心的。
19504
2019-08-26 09:40:43

大数据HIve数据仓库应用案例讲解分析
如今,大数据的大浪已经把我们每个人都卷入其中,随着大数据技术一起引起大众注意的还有HIve数据仓库。作为大数据分析的核心工具之一,它一直发挥着为企业提供决策支持的重要作用。因此掌握Hive是入门大数据学习的关键之一,下面我们就一起来看看HIve数据仓库应用案例讲解。
9938
2019-09-20 16:55:35

Kylin开发教程 从原理讲解到实践演练
众所周知,Kylin是一个可扩展的超快OLAP引擎,它能够提供Hadoop ANSI SQL借口和交互式查询,还可以和BI工具无缝整合,为百亿用户构建立方体。既然学习Kylin这么有必要,那么我们该如何学习它呢?这里为大家介绍博学谷的Kylin开发教程,本教程将会对Kylin进行系统化梳理,包括了Kylin的技术架构、运维不熟、增量构建、实时构建、性能优化等内容,带领大家从原理讲解到实战演练。
7636
2019-11-25 12:22:09
什么是数据可视化?三分钟快速解读
大数据时代如何做好数据分析是每个企业都在关注的问题,而数据可视化无疑是未来的发展趋势之一。相信大家对数据可视化并不陌生,但是大家真的了解什么是数据可视化吗?本文就用三分钟简单解读一下数据可视化的概念、发展、优势和工具,带大家快速了解和认识数据可视化。
10874
2019-11-29 16:51:22

Kafka的优势有哪些?经常应用在哪些场景?
Kafka的优势有哪些?经常应用在哪些场景?Kafka的优势比较多如多生产者无缝地支持多个生产者、多消费者、基于磁盘的数据存储、具有伸缩性、高性能轻松处理巨大的消息流。多用于开发消息系统,网站活动追踪、日志聚合、流处理等方面。今天我们一起来学习一下吧!
6759
2022-03-22 15:11:36



