在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
大数据Hadoop生态体系中常见的子系统有哪些?Hadoop是一个针对大量数据进行分布式处理的软件框架,是一个开发和运行处理大规模数据的软件平台,是Appach的一个用Java语言实现开源软件框架,实现在大量计算机组成的集群中对海量数据进行分布式计算,具有可靠、高效、可伸缩的特点,很多程序会用到这个框架。
今天就主要介绍下大数据Hadoop生态体系中常见的子系统:
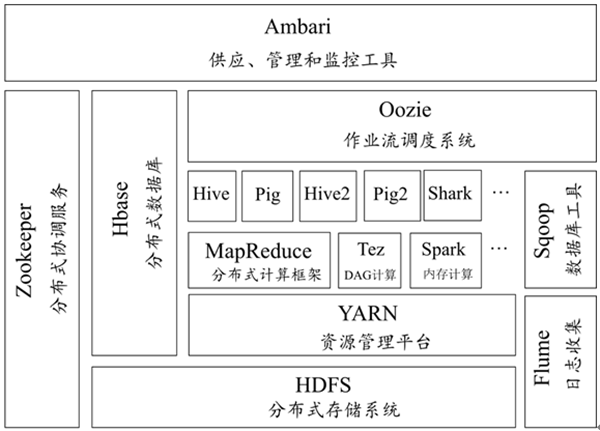
1、HDFS分布式文件系统
HDFS是Hadoop分布式文件系统,是Hadoop生态系统中的核心项目之一,是分布式计算中数据存储管理基础。HDFS具有高容错性的数据备份机制,它能检测和应对硬件故障,并在低成本的通用硬件上运行。另外,HDFS具备流式的数据访问特点,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
2、MapReduce分布式计算框架
MapReduce是一种计算模型,用于大规模数据集(大于1TB)的并行运算。“Map”对数据集上的独立元素进行指定的操作,生成键值对形式中间结果;“Reduce”则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这种“分而治之”的思想,极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
3、Yarn资源管理框架
Yarn是Hadoop2.0中的资源管理器,它可为上,层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。
4、Sqoop数据迁移工具
Sqoop是一款开源的数据导入导出工具,主要用于在Hadoop与传统的数据库间进行数据的转换,它可以将一个关系型数据库中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中,使数据迁移变得非常方便。
5、Mahout数据挖掘算法库
Mahout是Apache旗下的一个开源项目,它提供了一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐过滤、频繁子项挖掘。此外通过使用ApacheHadoop库Mahout可以有效地扩展到云中。
6、Hbase分布式存储系统
HBase是GoogleBigtable克隆版,它是一个针对结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。和传统关系数据库不同,HBase采用了BigTable的数据模型:增强的稀疏排序映射表(Key/Value),其中,键由行关键字、列关键字和时间戳构成。HBase提供了对大规模数据的随机、实时读写访问,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
7、Zookeeper分布式协作服务
Zookeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和HBase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等用于构建分布式应用,减少分布式应用程序所承担的协调任务。
Hive是基于Hadoop的一个分布式数据仓库工具,可以将结构化的数据文件映射为一张数据库表,将SQL语句转换为MapReduce任务进行运行。其优点是操作简单,降低学习成本,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
9、Flume日志收集工具
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方的能力。
大数据Hadoop生态体系中常见的子系统汇总:HDFS分布式文件系统、MapReduce分布式计算框架、Yarn资源管理框架、Sqoop数据迁移工具、Mahout数据挖掘算法库、Hbase分布式存储系统、Zookeeper分布式协作服务、Hive基于Hadoop的数据仓库、Flume日志收集工具等。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
Sequence File格式是什么?如何使用?
下一篇:
女生做大数据有发展前景吗?能学会吗?
相关推荐 更多

怎样学习spark
现在一提到云计算大数据,就会想到spark。要怎样学习spark呢?首先我们需要简单了解一下它:Spark 是一种与 Hadoop 相似的开源集群计算环境,甚至在某些工作负载方面表现得更加优越。Spark采用一个统一的技术堆栈解决了云计算大数据的如流处理、图技术、机器学习、NoSQL查询等方面的所有核心问题,具有非常完善的生态系统,这直接奠定了其一统云计算大数据领域的霸主地位;
9151
2019-08-06 10:20:49

大数据Apache Hadoop YARN 工作原理介绍
Apache Hadoop YARN是一种新的 Hadoop 资源管理器,通用资源管理系统可为上层应用提供统一的资源管理和调度,引入为集群在利用率、资源统一管理和数据共享等方面具有很强的优势。
7541
2020-04-27 14:27:28

零基础小白的大数据入门手册
零基础小白的大数据入门手册,学大数据前,大家可能听过不少说大数据难学、入行做好心理准备的。大家听完也很动摇很犹豫,怀疑自己能不能学好大数据。这其实完全没有必要,觉得一个东西难,百分之八十的原因是你不了解它。对于零基础小白而言想学大数据,首先了解下大致学习路径有个框架,知道学习的方向。
6188
2020-06-15 17:33:18

学大数据一定要学Java编程语言吗?
大数据相关岗位的就业薪资和发展前景,吸引了许多人纷纷参加培训机构以谋求一个就业机会。考察各个培训机构的课程,我们不难发现,不管哪个大数据培训机构的课程都涉及Java编程语言的学习。那么,学大数据一定要学Java编程语言吗?答案是不一定,如果你想从事大数据开发岗位,那一定要学Java编程语言。如果只是想往数据分析方向发展,那么学Python就足够了。
7275
2020-06-30 18:38:45

推荐零基础学习大数据的10本经典图书
学习大数据并不是一蹴而就的事情,及时工作多年的开发工程师都需要不断的补充新鲜的知识内容。目前学习大数据知识可以通过视频和图书两种方式学习,视频的优势在于能够将老师的个人开发经验传授给学习者,而图书的优势在于能够随时翻阅,内容比较丰富。这里为大家推荐零基础学习大数据的8本经典图书,希望同学们能够通过不同的学习途径充分掌握大数据开发技能。
7644
2020-09-14 16:01:31



