在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
本文就Hive数据仓库层级划分进行详细介绍,全文大概分为数据仓库的四个操作和四逻辑架构层次两个部分。这些都是Hive数据仓库的基础知识,大家一定要掌握哦!
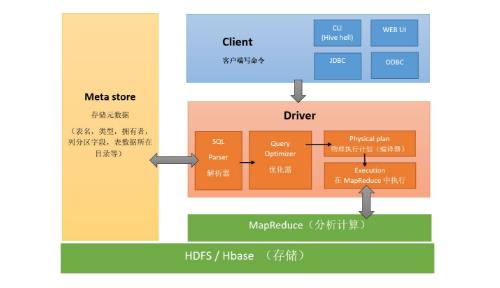
1.数据仓库的四个操作
ETL(extractiontransformation loading)负责将分散的、异构数据源中的数据抽取到临时中间层后进行清洗、转换、集成,最后加载到数据仓库或数据集市中。ETL 是实施数据仓库的核心和灵魂,ETL规则的设计和实施约占整个数据仓库搭建工作量的 60%~80%.
(1)数据抽取(extraction)包括初始化数据装载和数据刷新:初始化数据装载主要关注的是如何建立维表、事实表,并把相应的数据放到这些数据表中;而数据刷新关注的是当源数据发生变化时如何对数据仓库中的相应数据进行追加和更新等维护(比如可以创建定时任务,或者触发器的形式进行数据的定时刷新)。
(2)数据清洗主要是针对源数据库中出现的二义性、重复、不完整、违反业务或逻辑规则等问题的数据进行统一的处理。即清洗掉不符合业务或者没用的的数据。比如通过编写hive或者MR清洗字段中长度不符合要求的数据。
(3)数据转换(transformation)主要是为了将数据清洗后的数据转换成数据仓库所需要的数据:来源于不同源系统的同一数据字段的数据字典或者数据格式可能不一样(比如A表中叫id,B表中叫ids),在数据仓库中需要给它们提供统一的数据字典和格式,对数据内容进行归一化;另一方面,数据仓库所需要的某些字段的内容可能是源系统所不具备的,而是需要根据源系统中多个字段的内容共同确定。
(4)数据加载(loading)是将最后上面处理完的数据导入到对应的存储空间里(mysql等)以方便给数据集市提供,进而可视化。一般大公司为了数据
安全和操作方便,都是自己封装的数据平台和任务调度平台,底层封装了大数据集群比如hadoop集群,spark集群,sqoop,hive,zookeepr,hbase等只提供web界面,并且对于不同员工加以不同权限,然后对集群进行不同的操作和调用。以数据仓库为例,将数据仓库分为逻辑上的几个层次。这样对于不同层次的数据操作,创建不同层次的任务,可以放到不同层次的任务流中进行执行(大公司一个集群通常每天的定时任务有几千个等待执行,甚至上万个,所以划分不同层次的任务流,不同层次的任务放到对应的任务流中进行执行,会更加方便管理和维护)。
2.数据仓库的四个逻辑架构层次
数据仓库标准上可以分为四层。但是注意这种划分和命名不是唯一的,一般数仓都是四层,但是不同公司可能叫法不同。比如这里的临时层叫复制层SSA,京东则叫BDM。同样阿里巴巴却是五层数仓结构,更加详细,但是核心的理念都是从四层数据模型而来。
(1)复制层(SSA,system-of-records-staging-area)
SSA 直接复制源系统(比如从mysql中读取所有数据导入到hive中的同结构表中,不做处理)的数据,尽量保持业务数据的原貌;与源系统数据唯一不同的是,SSA 中的数据在源系统数据的基础上加入了时间戳的信息,形成了多个版本的历史数据信息。
(2)原子层(SOR,system-of-record)
SOR 是基于模型开发的一套符合 3NF 范式规则的表结构,它存储了数据仓库内最细层次的数据,并按照不同的主题域对数据分类存储;比如高校数据统计服务平台根据目前部分需求将全校数据在 SOR 层中按人事、学生、教学、科研四大主题存储;SOR 是整个数据仓库的核心和基础,在设计过程中应具有足够的灵活性,以能应对添加更多的数据源、支持更多的分析需求,同时能够支持进一步的升级和更新.
(3)汇总层(SMA,summary-area)
SMA 是 SOR和DM(集市层) 的中间过渡,由于 SOR 是高度规范化数据,此要完成一个查询需要大量的关联工作,同时DM 中的数据粒度往往要比 SOR 高很多,对要生DM 中的汇总数据需要进行大量的汇总工作,此,SMA 根据需求把 SOR 数据进行适度的反范(例如,设计宽表结构将人员信息、干部信息等多表的数据合并起来)和汇总(例如,一些常用的头汇总、机构汇总等);从而提高数据仓库查询性能。
(4)集市层/展现层(DM, data mart)
DM 保存的数据供用户直接访问的:可以将 DM 理解成最终用户接最终想要看的数据;DM 主要是各类粒度的事数据,通过提供不同粒度的数据,适应不同的数访问需求;高校数据统计服务平台 DM 中的数据。
以上就是Hive数据仓库层级划分介绍,大家都记住了吗?
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
大数据时代带给我们的重大变革
下一篇:
数据分析对企业经营的作用和现实意义
相关推荐 更多

大数据技术自学能学会吗?大数据应该如何自学?
大数据本质也是数据,但是又有了新的特征,包括数据来源广、数据格式多样化(结构化数据、非结构化数据、Excel文件、文本文件等)、数据量大(最少也是TB级别的、甚至可能是PB级别)、数据增长速度快等。那大数据技术自学能学会吗?大数据应该如何自学呢?
8670
2019-08-14 10:21:23

零基础学大数据现实吗?需要经历哪些过程?
零基础学大数据现实吗?需要经历哪些过程?首先我们要明白学习任何东西都是从无到有,零基础学习大数据并没有什么劣势,只不过是比有一定编程基础的学习者多付出一些努力,因此不要随意给自己设限,认为零基础这不能学,那不能学。其次零基础学习者要学好大数据无外乎两点,一是清晰的学习内容规划,二是适合自己的学习模式。下面小编就来讲讲零基础如何学习大数据。
8945
2019-10-09 16:02:32

Flink从入门到实践课程介绍
Flink是解放程序员的一款开源大数据计算引擎,本文将为大家介绍Flink从入门到实践的课程详情,主要包括课程的学习内容、亮点特色和学习收获,对Flink感兴趣或者有学习需要的小伙伴可以看一看。
6136
2020-04-21 18:22:10

什么是数据库?用来做什么?
什么是数据库?用来做什么?我们在编程和网络经常会听到数据可这个词,作为市场调研和用户分析的重要工具,那么究竟什么是数据库?数据库是存放数据的仓库。它的存储空间很大,可以存放百万条、千万条、上亿条数据。但是数据库并不是随意地将数据进行存放,是有一定的规则的,否则查询的效率会很低。
6601
2020-06-03 14:16:12
分布式系统学习笔记
分布式系统其实就是为了处理更多数据而存在的。对于大数据学习者来讲,分布式系统入门还是很容易的。本文为大家总结整理了一篇关于分布式系统的学习笔记,主要内容有分布式系统的定义、常用分布式方案以及分布式和集群的对比,下面一起来看看吧~
7161
2020-06-09 11:12:49



