在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
缓存如何分类?缓存分类按照系统划分为应用级缓存和系统级别缓存;按照设计分本地缓存、分布式缓存、多级缓存。在技术界“缓存为王”,从浏览器到应用前端、应用后端、数据库,每一层都能通过缓存来提高系统的扩展能力,改善系统的响应能力同时减少系统的负担。
一、按照系统划分
1、应用级缓存
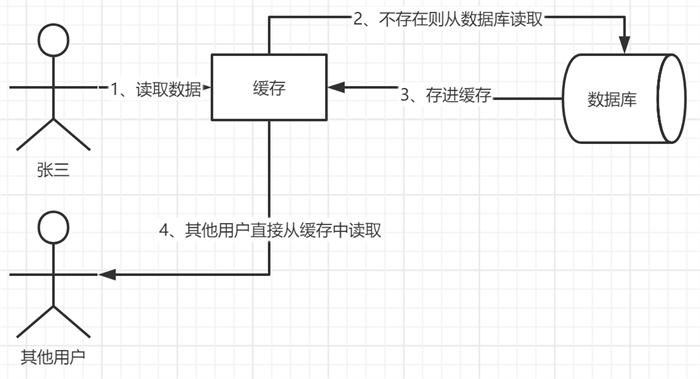
应用级缓存是我们平时写的应用程序中所使用的缓存。在平时程序中一般是按照如下操作流程来实现缓存的操作,首先张三用户读取数据库,并将读取的数据存入到缓存中,其他用户读取的时直接从缓存中读取,而不用查询数据库,从而提高程序的执行速度和效率。
2、系统级别缓存
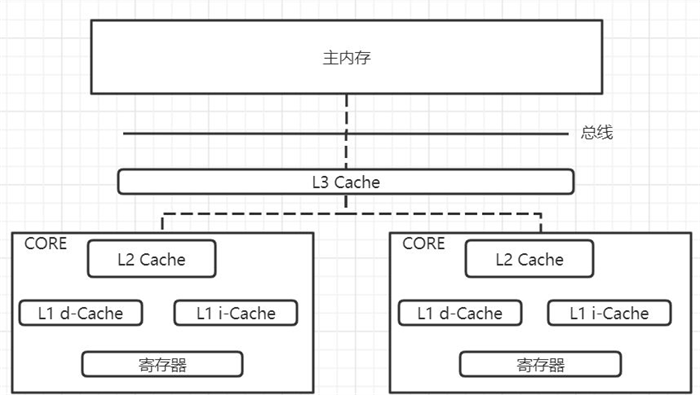
系统级别缓存是抛开我们应用程序之外硬件的缓存操作,例如某些CPU的缓存操作和如下图多级缓存流程类似, CPU在操作数据的时候,先读取1级缓存,1级缓存如果没有数据则读取2级缓存,2级缓存没有数据则读取3级缓 存,3级缓存如果没有数据就直接从主存储器(存储指令和数据)读取数据;
二、按照设计分
(1)本地缓存
直接运行在应用程序本地的缓存组件, 比如 JVM 中的 Map 数据结构,可以作为最简单的数据缓存:
class LocalCache {
private static Map<String, Object> cache = new HashMap<>();
private LocalCache() {}
public static void put(String key, Object value) { cache.put(key, value); }
public static Object get(String key) { return cache.get(key); }
}
如果你的应用程序只需要运行在一台服务器上,并且多个应用程序之间不需要共享缓存的数据(比如用户 token),可以直接采用本地缓存,访问缓存时不需要通过网络传输,非常地方便迅速。
但是本地缓存会和你的应用程序强耦合,应用程序停止,本地缓存也就停止了,而且如果是在分布式场景下,多个机器都要使用缓存,此时如果在每个服务器上单独维护一份本地缓存,不仅无法共享数据,而且非常浪费内存(因为每台机器可能缓存了相同的数据)。

(2)分布式缓存
分布式缓存是指独立的缓存服务,不和任何一个具体的应用耦合,可以独立运行并搭建缓存集群。类似数据库,所有的应用程序都可以连接同一个缓存服务以获取相同的缓存数据。
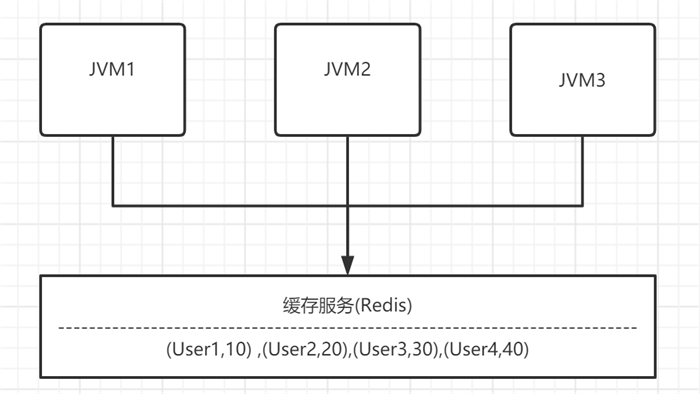
除了数据共享外,分布式缓存的优点还有很多,比如不需要每台机器单独维护缓存、可以集中管理缓存和整体管控分析、便于扩展和容错等,但是应用必须要通过网络访问分布式缓存服务,会产生额外的网络开销成本。并且每台机器都有可能会对整个分布式缓存服务产生影响,而一旦分布式缓存挂了,所有的应用都可能出现瘫痪(缓存雪崩)。
(3)多级缓存
上述两种缓存没有绝对的优劣,要根据实际的业务场景进行选型。其实还可以将本地缓存与分布式缓存相结合,形成多级缓存服务,架构如下:
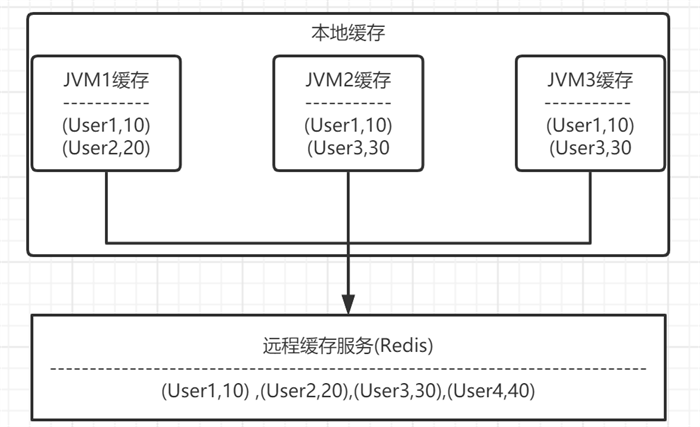
当首次查询时不存在缓存会同时将数据写入本地缓存和分布式缓存,之后的查询优先查询分布式缓存,而如果分布式缓存宕机,则从本地缓存获取数据,通过多级缓存机制,能够起到兜底的作用,即使缓存挂掉,也能支撑应用运行一段时间。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
缓存是什么?为什么要使用缓存?
下一篇:
开发人员该选择什么大数据工具提高工作效率?
相关推荐 更多

5分钟掌握Hadoop环境搭建流程
Hadoop是大数据技术的基础,它在大数据技术体系中的地位是非常重要的。目前Hadoop是主流的分布式系统基础架构之一,用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。所以对于Hadoop基础知识的掌握的扎实程度,会决定你在大数据技术道路上走多远。首先我们来学习一下Hadoop环境搭建流程吧。
9939
2019-08-14 10:19:35

大数据应用的重要性体现在方方面面
自全国提出“数据中国”的概念以来,我们周围默默地在发挥作用的大数据逐渐深入人们的心中,大数据的应用也越来越广泛,具体到金融、汽车、餐饮、电信、能源、体育和娱乐等领域,下面就通过本文,让我们看看这些正在发生在我们身边的大数据应用案例。
9220
2020-07-06 14:59:59

数据分析师获取数据的方式有哪些?
数据分析师工作的第一步就是获取数据,也就是数据采集。获取数据的方式有很多,本文将着重介绍一下数据分析中的数据来源。一般来讲,数据来源主要分为两大类,企业外部来源和内部来源。其中外部来源包括外部购买、网络爬取、免费开源数据等,内部数据来源包括销售数据、考勤数据、财务数据等。
9969
2020-08-07 18:19:53

开发人员该选择什么大数据工具提高工作效率?
开发人员该选择什么大数据工具提高工作效率?海量数据使得数据分析工作变得繁重困难,开发人员选择合适的大数据工具来开发大数据系统成为新的挑战。因此开发人员要根据不同的数据处理方式对大数据工具进行分类。
4907
2022-04-14 13:56:44

大数据的属性是什么?如何划分?
大数据的属性是什么?如何划分?拥有大数据是件令人兴奋的事,但在实践中处理大数据存在一定的困难,如数据量过大事情就会变得更困难。为了处理大数据要采用高性能算法,这些算法也已展现出惊人的优越性。
6699
2022-05-04 15:28:28



