在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
Kafka是由Java编写的一个开源流处理平台,因为它强大的动作流数据处理功能而备受大数据开发者的欢迎。因而作为大数据的开发者,掌握Kafka也就掌握了大数据最重要的一项核心技术。本文是一篇新手入门Kafka的安装教程,下面小编将手把手结合图片详细的指导大家安装Kafka。

1、认识Kafka
Kakfa 是一个分布式的基于发布/订阅模式的消息队列(message queue),所谓的消息队列是指一个用户要注册信息,当用户信息写入数据库后,后面还有一些其他流程,比如发送短信,则需要等这些流程处理完成后,再返回给用户。Kafka 的基础架构主要有 broker、生产者、消费者组构成,当前还包括 ZooKeeper。目前Kakfa主要应用于大数据的实时处理领域。
2、 安装 Kafka
步骤一:Kafka 的安装只需要解压安装包就可以完成安装。
tar -zxvf kafka_2.11-2.1.1.tgz -C /usr/local/
步骤二: 查看配置文件。
[root@es1 config]# pwd
/usr/local/kafka/config
[root@es1 config]# ll
total 84
-rw-r--r--. 1 root root 906 Feb 8 2019 connect-console-sink.properties
-rw-r--r--. 1 root root 909 Feb 8 2019 connect-console-source.properties
-rw-r--r--. 1 root root 5321 Feb 8 2019 connect-distributed.properties
-rw-r--r--. 1 root root 883 Feb 8 2019 connect-file-sink.properties
-rw-r--r--. 1 root root 881 Feb 8 2019 connect-file-source.properties
-rw-r--r--. 1 root root 1111 Feb 8 2019 connect-log4j.properties
-rw-r--r--. 1 root root 2262 Feb 8 2019 connect-standalone.properties
-rw-r--r--. 1 root root 1221 Feb 8 2019 consumer.properties
-rw-r--r--. 1 root root 4727 Feb 8 2019 log4j.properties
-rw-r--r--. 1 root root 1925 Feb 8 2019 producer.properties
-rw-r--r--. 1 root root 6865 Jan 16 22:00 server-1.properties
-rw-r--r--. 1 root root 6865 Jan 16 22:00 server-2.properties
-rw-r--r--. 1 root root 6873 Jan 16 03:57 server.properties
-rw-r--r--. 1 root root 1032 Feb 8 2019 tools-log4j.properties
-rw-r--r--. 1 root root 1169 Feb 8 2019 trogdor.conf
-rw-r--r--. 1 root root 1023 Feb 8 2019 zookeeper.properties
(3)修改配置文件 server.properties。
设置 broker.id 这个是 Kafka 集群区分每个节点的唯一标志符。
步骤三:设置 Kafka 的数据存储路径。

步骤四:设置是否可以删除 topic,默认 Kafka 的 topic 是不允许删除的。

步骤五:Kafka 的数据保留的时间,默认是 7 天。
步骤六:Log 文件最大的大小,如果 log 文件超过 1 G 会创建一个新的文件。
![]()
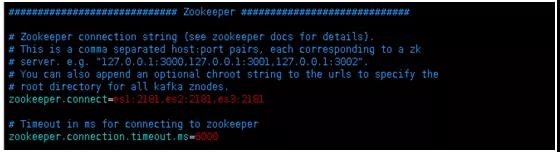
步骤七:Kafka 连接的 ZooKeeper 的地址和连接 Kafka 的超时时间。
![]()
步骤八:默认的 partition 的个数。
步骤九:安装成功,启动 Kafka,每个 Kakfa 节点都需要手动启动,下面的方式阻塞的方式启动。
如何安装Kafka?相信大家看完新手安装Kafka教程指导,对于这个问题应该已经有了自己的答案。当然安装Kafka只是第一步,要想更加深入学习大数据的相关技术,可以来博学谷报名相关课程。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
影响大数据与分析的因素有哪些?
下一篇:
大数据疫情防控应用 大数据与个人隐私之间存在的冲突
相关推荐 更多

数据分析的行业前景如何?为什么要学习数据分析?
数据分析岗位一直存在,但是在大数据时代的快速发展过程中,数据分析再次成为焦点。企业对于数据分析的需求也越来越大。面对数据分析的高薪就业市场,依旧有很多小伙伴处在观望阶段,今天就和大家一起了解一下数据分析的行业前景如何,为什么要学习数据分析。
9033
2019-09-03 18:44:35

什么是大数据分析?大数据分析概念
大数据分析指对规模巨大的数据进行分析。大数据特点 数据量大、速度快、类型多、价值、真实性。随着大数据的发展,大数据分析应运而生。数据分析让人们对数据产生更加优质的诠释,而具有预知意义的分析可以让分析员根据可视化分析和数据分析后的结果做出一些预测性的推断。
8305
2020-04-27 15:15:39

数据分析的基本步骤是什么?
相信大家对数据分析已经不陌生了,那数据分析的基本步骤是什么,大家都知道吗?一般来讲,典型的数据分析包含六个步骤,分别是明确思路、收集数据、处理数据、分析数据、展现数据以及撰写报告,下面我们具体讲一讲数据分析的六大步骤。
12908
2020-06-02 11:20:17

2021年大数据发展趋势及动态
大数据已经走单纯的技术架构和技术体系,走向了社会基础设施。2020年“新基建”就将“大数据中心”定义为数字新基础设施的重要建设内容。基于隐私计算的数据流通技术成为实现数据联合计算的主要思路。隐私计算在保护数据本身不对外泄露的前提下实现了数据融合,为安全合规的数据流通带来了可能。
7065
2021-01-19 15:12:03

Apache Spark与 Apache Hadoop数据科学工具有哪些区别?
Apache Spark被设计为大规模处理的接口,而 Apache Hadoop 为大数据的分布式存储和处理提供了更广泛的软件框架。两者既可以一起使用也可以作为独立服务使用。Apache Spark 和 Apache Hadoop 都是 Apache 软件基金会提供的流行的开源数据科学工具,由社区开发和支持受欢迎程度和功能不断增长。
4873
2022-06-02 11:25:53



