在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
Logstash开发采集上亿级别数据,需求属于日志采集的范畴,Logstash本身不支持反序列化功能,需要自定义开发ruby插件来支持,使用MLSQL结合UDF的方式进行流式处理。MLSQL写入hdfs会产生大量的小文件,需要单独开发合并文件的功能,写入es的数据是需要数仓结合其他业务数据进行建模,用离线处理的方式。
开发背景:公司业务系统做优化改造,同时为了能够实现全链路监控需收集所有业务系统之间的调用日志;数据情况:每天20亿以上;机器成本:3台kafka集群;2台logstash采集机器;技术:Java,MQ,MLSQL,Logstash。
采集流程:
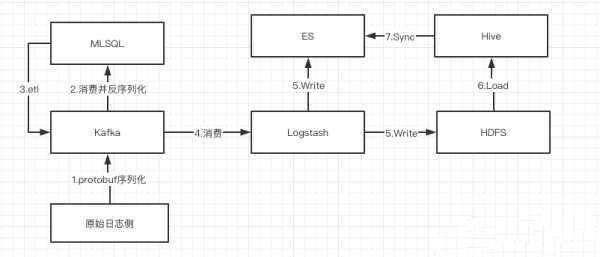
MLSQL 消费MQ:原始日志产生侧通过protobuf进行序列化推送至mq,然后通过MLSQL进行反序列化并进行简单的etl处理后,再推送至MQ;
通过Logstash进行消费MQ:通过logstash消费经过MLSQL处理后的数据,并在这里通过ruby进行再次的加工处理,最后写入es和hdfs(一部分流程推送到es是业务侧使用,而另一部分写入hdfs是提供给数仓使用)
数仓建模:通过数仓建模,将最后的指标结果推送至es提供给业务侧使用,主要是借鉴这个需求讲解Logstash在实际场景中的使用以及优化。
Logstash开发流程:
1、确定日志格式
一个日志文件里肯定是不止一种日志格式,也有可能是标准化的格式,这里需要跟日志产生侧进行确认格式。
2、调试grok
确定好日志格式后,编写grok语法,然后进行调试,本人是通过kibana6自带的grok debug进行调试。结合该需求背景,最后经过logstash采集的时候,其实已经通过MLSQL进行了处理,最后Logstash消费的是格式就是一个json字符串,所以不需要grok语法。
3、调试ruby
结合该需求,使用ruby进行一些清洗逻辑
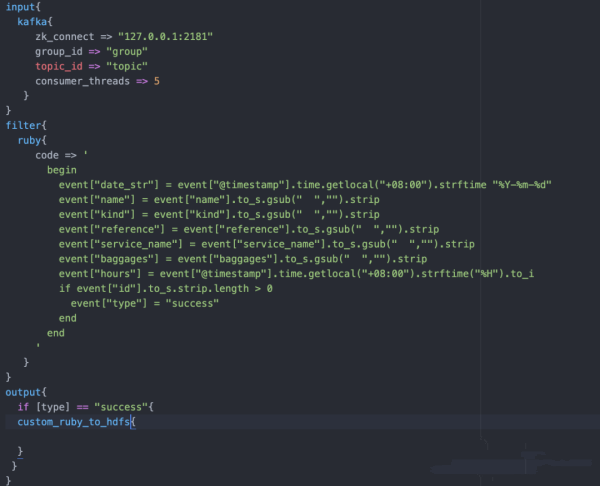
4、优化
优化工作在整个需求开发周期的比例较大,数据量较大资源较少,具体优化思路如下:
(1)MLSQL优化
这部分的优化工作主要是在反序化这块,剔除一部分无用字段,以及提前过滤一部分数据量,一部分注册UDF的代码:

(2)Kafka端优化
因kafka集群是集团共用,所以kafka端的优化其实只涉及到消费端的优化。这里只调节数据压缩、消费者线程数这两个参数。
(3)hdfs优化
logstash写入hdfs的部分不用使用自带的webhdfs插件,而是自定义的插件。
因自定义插件中涉及到文件锁的问题,会通过比对前后两次文件是否一致来进行文件最后的刷写,所以这里只能通过减少文件的更新频率来减少上下文的切换以及刷写操作
(4)ES优化
es部分的优化也只是涉及到写优化,比如批量写入、调大线程数、增加refresh间隔、禁止swapping交换内存、禁止refresh和replica操作,调大index buffer等操作。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
零基础报Java培训班学4个月有用吗?学习效果如何?
下一篇:
Spring AOP应用场景有哪些?Aop工作原理分析
相关推荐 更多

Java程序员面试必备 经典Java面试题分享
Java程序员是企业软件开发的核心人员,所以企业在招聘Java程序员的时候都会经过严格的选拔,包括面试与笔试环节,其核心是为了考察Java程序员的技术掌握能力以及工作中解决问题的能力。而且通过面试题,程序员还可以了解目前企业比较核心的技术要求是什么。所以作为Java程序员在研究新技术的同时也要多看一下面试题分享。下面就和大家分享Java程序员面试必备的一些经典Java面试题。
8194
2019-06-18 17:19:17

Java入门比较好的书是哪本?Java入门教材推荐
Java入门最好的书是哪本?对于刚刚入门Java的初学者而言,第一本Java入门教材必须要通俗易懂,最好能把理论知识和实战练习结合起来,而满足上述条件的书籍非《Java基础入门》莫属。《Java基础入门》是由传智播客高教产品研发部,为零基础初学者专门编著的Java学习教材。下面我们来看看这本书的详细内容吧!
8216
2019-12-05 13:09:05

分布式和微服务是什么关系?
分布式和微服务是什么关系?简单来说,分布式和微服务的概念比较相似,分布式属于微服务。但是分布式和微服务在架构、作用和粒度上有所区别。因此,两者的关系是既相互联系又相互区别。本文主要带大家认识分布式和微服务,并探讨一下两者的关系,感兴趣的小伙伴可以接着看下去
21315
2019-11-01 16:02:32

0基础自学Java可行吗?
0基础自学Java可行吗?这个问题没有人可以打包票告诉你一个准确的答案,毕竟每个人的学习能力和天赋都是不一样的,但是有一点可以确定,只要找准了方向,愿意踏踏实实的努力学习,完全0基础也可以学好Java。因此对于零基础的学习者而言,要思考的不是自己行不行,而是应该怎么做。只有在摆正了学习心态的基础上,我们才能来讨论自学Java的相关问题。
6467
2020-04-17 18:55:52

Java架构师应具备的职业技能有哪些?
Java架构师应具备的职业技能有哪些? 在互联网开发领域架构师可以分为业务架构师、中间件架构师、系统架构师。如何区分三者的区别方法很简单,可以去招聘网站看看,了解架构师相关的招聘需求是什么样的。
5453
2022-04-27 11:26:56



