在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
为什么要使用Redis?其实是因为Redis是一个性能强劲且具有复制特性的远程内存数据库,它的数据模型更是为解决问题而生。下面小编来详细解析一下Redis。

有memcached使用经验的人可能知道,用户只能用APPEND命令将数据添加到已有字符串的末尾。memcached的文档中声明,可以用APPEND命令来管理元素列表。这很好!用户可以将元素追加到一个字符串的末尾,并将那个字符串当作列表来使用。但随后如何删除这些元素呢?memcached采用的办法是通过黑名单(blacklist)来隐藏列表里面的元素,从而避免对元素执行读取、更新、写入(包括在一次数据库查询之后执行的memcached写入)等操作。相反地,Redis的LIST和SET允许用户直接添加或者删除元素。
使用Redis而不是memcached来解决问题,不仅可以让代码变得更简短、更易懂、更易维护,而且还可以使代码的运行速度更快(因为用户不需要通过读取数据库来更新数据)。除此之外,在其他许多情况下,Redis的效率和易用性也比关系数据库要好得多。
数据库的一个常见用法是存储长期的报告数据,并将这些报告数据用作固定时间范围内的聚合数据(aggregates)。收集聚合数据的常见做法是:先将各个行插入一个报告表里面,之后再通过扫描这些行来收集聚合数据,并根据收集到的聚合数据来更新聚合表中已有的那些行。之所以使用插入行的方式来存储,是因为对于大部分数据库来说,插入行操作的执行速度非常快(插入行只会在硬盘文件末尾进行写入)。不过,对表里面的行进行更新却是一个速度相当慢的操作,因为这种更新除了会引起一次随机读(random read)之外,还可能会引起一次随机写(random write)。而在Redis里面,用户可以直接使用原子的(atomic)INCR命令及其变种来计算聚合数据,并且因为Redis将数据存储在内存里面2,而且发送给Redis的命令请求并不需要经过典型的查询分析器(parser)或者查询优化器(optimizer)进行处理,所以对Redis存储的数据执行随机写的速度总是非常迅速的。
使用 Redis 而不是关系数据库或者其他硬盘存储数据库,可以避免写入不必要的临时数据,也免去了对临时数据进行扫描或者删除的麻烦,并最终改善程序的性能。虽然上面列举的都是一些简单的例子,但它们很好地证明了“工具会极大地改变人们解决问题的方式”这一点。
除了第6章提到的任务队列(task queue)之外,本书的大部分内容都致力于实时地解决问题。本书通过展示各种技术并提供可工作的代码来帮助读者消灭瓶颈、简化代码、收集数据、分发(distribute)数据、构建实用程序(utility),并最终帮助读者更轻松地完成构建软件的任务。只要正确地使用书中介绍的技术,读者的软件就可以扩展至令那些所谓的“Web扩展技术(web-sacle technology)”相形见绌的地步。
相信大家现在已经了解了Redis是什么、它的作用是什么以及为什么要使用它。不过实践出真知,要想真正掌握Redis,还是多多练习使用它吧!
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
HTTP与HTTPS有什么区别和联系?
下一篇:
零基础怎么学Python?Python学习指南
相关推荐 更多

Python中常用图像处理工具
图像处理技术是互联网开发一个非常重要的环节。图像处理中的常见任务包括显示图像,基本操作(如剪切、翻转、旋转等),图像分类和特征提取、图像恢复、和图像识别。尤其在人工智能技术日臻成熟的现在,图像处理技术成为Python开发工程师必备的技能之一。Python编程语言自身提供许多先进的图像处理工具,使得Python成为图像处理任务的最佳选择。
7215
2019-10-28 18:53:24

Python中with语句的用法介绍
Python中的with语句,在事前需要设置和事后需要清理的场景下,能够提供非常方便的处理方式。因此,本文就来和大家介绍一下with语句的用法,具体内容包括with语句简介、With语句的基本语法格式、参数说明、with语句的工作原理和示例代码,希望能够帮助到Python的学习者。
7686
2019-11-04 17:51:38

如何提高Pandas的运行速度?四大性能优化方法
Pandas作为数据分析的屠龙宝刀,毫不夸张的说,功能和优势都极其强大。像是支持GB数据处理,多样的数据清洗方法;支持多种开源可视化工具包,更加丰富的数据成果展示等等。因此如果能做好性能优化,就可以极大的提高Pandas的运行速度。本文为大家总结了四大优化Pandas性能的方法,感兴趣的朋友就赶紧看下去吧!
12744
2019-12-23 11:00:02

学Python需要什么基础知识?
学Python需要什么基础知识?学习Python语言并没有过多的要求,需要基本的阅读理解能力和会简单的计算机操作。很多人学习了Python的基础知识后进入了迷茫期,学会了基础的语法,但做不了项目不知道从何下手,因此在学习过程中应该多动手练习,将知识点运用到小项目中去。
6736
2020-03-20 14:40:35
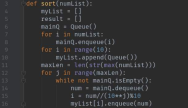
Python数据结构之字典学习笔记
对于许多Python初学者来讲,数据结构中的字典是一个不容易理解的概念。字典作为一种容器型数据结构,它也可以算得上是最有用的容器。下面是小编整理的相关学习笔记,让我们一起来好好地学习有关于字典的语法知识吧~
6165
2020-05-05 12:04:36



