在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
很多人喜欢将python作为自己的主开发语言,不仅仅是因为python的功能强大,更重要的是Python的代码简单易上手,并且相对应用领域非常广泛。想学习python的朋友一般都会从学习基础语言或者爬虫开始。那如何实现python爬虫?python爬虫好学吗?小编就和大家一起了解一下。

一:爬虫准备
1.爬虫首先需要做的事情就是要确定好你想要爬取数据的对象,这里我将以百度主页logo图片的地址为例进行讲解。
2.首先,是打开百度主页界面,然后把鼠标移动到主页界面的百度logo图标上面,点击鼠标右键,然后点击审查元素,即可打开开发者界面。
3.然后再下面的界面里面,可以看到该logo图标在HTML里面的排版模式,<img hidefocus="true" src="//百度/img/bd_logo1.png" width="270" height="129">,这里百度我用字替换了。
二:开始爬虫
1.爬虫主要分为两个部分,第一个是网页界面的获取,第二个是网页界面的解析;爬虫的原理是利用代码模拟浏览器访问网站,与浏览器不同的是,爬虫获取到的是网页的源代码,没有了浏览器的翻译效果。
2.首先,我们进行页面获取,python爬虫的话很多模块包提供给开发者直接抓取网页,urllib,urllib2,requests(urllib3)等等,这里我们使用urllib2进行网站页面的获取;首先导入urllib2模块包(该包是默认安装的):import urllib2
3.导入模块包之后,然后调用urllib2中的urlopen方法链接网站,代码如下repr = urllib2.urlopen("XXXXXX"),XXXXXX代表的是网站名称。
4.得到网站的响应之后,然后就是将页面的源代码读取出来,调用read方法,html = repr.read()
5.获取到页面的源代码之后,然后接下来的工作就是将自己想要的数据从html界面源代码中解析出来,解析界面的模块包有很多,原始的re,好用的BeautifulSoup,以及高大上的lxml等等,这里我就简单的用re介绍介绍,首先导入re模块包:import re
6.然后进行利用re进行搜索,这里我有使用正则表达式,看不懂的同学需去补充点正则表达式方面的知识。
7.然后,我这里就实现了一个简单的爬虫流程,打印url,可以看见刚好就是之前我们看见的百度主页logo的地址。
8.源代码:
import urllib2
repr = urllib2.urlopen("URL")
html = repr.read()
import re
省略一行代码
print url
以上就是和大家分享的实现爬虫的一个真实案例。希望大家能够对爬虫有一个了解。当然在python学习中一定要自己亲手联系,目前企业对于求知者的要求更加注重其实战能力。所以掌握爬虫技术仅仅是入门,最好是能够熟练的应用。
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
零基础学Python哪里好?为什么?
下一篇:
Lambda表达式在Python中的优点和缺点
相关推荐 更多

学会Python爬虫能赚大钱吗?Python爬虫赚钱渠道分享
学会Python爬虫能赚大钱么?首先大家要明白这个只是作为一个技术兼职,赚点外快,肯定不比程序员全职工作的工资高。其次赚的多少还要看大家赚钱的渠道。下面小编就和大家分享一下,Python爬虫赚钱渠道,希望对大家有所帮助。
14858
2019-08-26 11:34:54

Python正则表达式例子讲解
因为字符串处理无所不在,正则毫无疑问是最简洁和高效的处理方法。今天我们要来一起梳理的知识点就是Python正则表达式。本文将用十个Python正则表达式的例子,帮助初学者入门Python正则表达式,下面一起来看看吧~
6288
2020-06-04 10:18:01

Python运算符总结
所有的编程语言本质就是在解决运算逻辑,通过各种算法实现想要的各种功能,因此在学习Python编程语言时,不仅要掌握各种变量类型,深刻理解函数式编程的原理,还要彻底搞懂各类运算符的使用。通过本片文章你可以了解到在Python编程开发中的各类运算符以及其使用方法。
8600
2020-06-08 16:31:37

Jquery如何获取和设置元素内容?代码怎么写?
Jquery如何获取和设置元素内容?代码怎么写?jQuery 具有可操作 HTML 元素和属性的方法,其中jQuery 非常重要的部分就是操作DOM,获得- text()、html() 以及 val()内容。
5050
2022-01-05 09:32:48
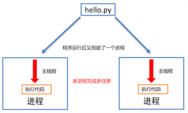
进程是什么?进程的作用是什么?
进程是什么?进程的作用是什么?进程是实现多任务的一种方式,一个正在运行的程序或者软件就是一个进程,是操作系统进行资源分配的基本单位也就是说每启动一个进程。一个正在运行的程序或者软件就是一个进程,它是操作系统进行资源分配的基本单位,也就是说每启动一个进程。
12183
2022-03-30 16:05:13



