在线客服

扫描二维码
下载博学谷APP
扫描二维码
关注博学谷微信公众号
如今,通过线程池最大程度利用CPU的多核性能是十分常见的基础操作。与此同时线程池的优势是显而易见的,它可以降低系统资源消耗,提高系统响应速度,方便线程并发数的管控等等。那么线程池的实现是怎么样的呢?本文将带大家分析线程池的具体业务场景,现在让我们开始吧~
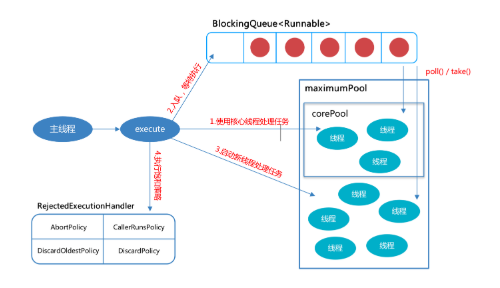
一、业务场景
快速响应用户请求是线程池十分常见的业务场景。具体来讲就是用户发起的实时请求,服务追求响应时间。比如说用户要查看一个商品的信息,那么我们需要将商品维度的一系列信息如商品的价格、优惠、库存、图片等等聚合起来,展示给用户。
除此之外,快速处理批量任务也是我们会遇到的业务场景。离线的大量计算任务,需要快速执行。比如说,统计某个报表,需要计算出全国各个门店中有哪些商品有某种属性,用于后续营销策略的分析,那么我们需要查询全国所有门店中的所有商品,并且记录具有某属性的商品,然后快速生成报表。
二、使用分析
针对快速响应用户请求的业务场景,我们应该从用户体验角度看,这个结果响应的越快越好,如果一个页面半天都刷不出,用户可能就放弃查看这个商品了。而面向用户的功能聚合通常非常复杂,伴随着调用与调用之间的级联、多级级联等情况,业务开发同学往往会选择使用线程池这种简单的方式,将调用封装成任务并行的执行,缩短总体响应时间。另外,使用线程池也是有考量的,这种场景最重要的就是获取最大的响应速度去满足用户,所以应该不设置队列去缓冲并发任务,调高corePoolSize和maxPoolSize去尽可能创造多的线程快速执行任务。
至于快速处理批量任务,这种场景需要执行大量的任务,我们也会希望任务执行的越快越好。这种情况下,也应该使用多线程策略,并行计算。但与响应速度优先的场景区别在于,这类场景任务量巨大,并不需要瞬时的完成,而是关注如何使用有限的资源,尽可能在单位时间内处理更多的任务,也就是吞吐量优先的问题。所以应该设置队列去缓冲并发任务,调整合适的corePoolSize去设置处理任务的线程数。在这里,设置的线程数过多可能还会引发线程上下文切换频繁的问题,也会降低处理任务的速度,降低吞吐量。
三、结论与反思
线程池使用面临的核心的问题在于线程池的参数并不好配置。一方面线程池的运行机制不是很好理解,配置合理需要强依赖开发人员的个人经验和知识;另一方面,线程池执行的情况和任务类型相关性较大,IO密集型和CPU密集型的任务运行起来的情况差异非常大,这导致业界并没有一些成熟的经验策略帮助开发人员参考。
以上就是线程池的具体业务场景分析,大家都理解了吗?如果大家想要继续深入学习并发编程的相关知识点,可以在博学谷学习课程《Java并发编程高阶技术实践》,课程进入链接:https://www.boxuegu.com/course/detail-1515.html
— 申请免费试学名额 —
在职想转行提升,担心学不会?根据个人情况规划学习路线,闯关式自适应学习模式保证学习效果
讲师一对一辅导,在线答疑解惑,指导就业!
上一篇:
Java程序员Dubbo面试题整理附答案
下一篇:
Spring配置数据源详解
相关推荐 更多

Overload 和 Override 的区别,Overloaded 改变返回值的类型?
Overload 和 Override 的区别。Overloaded 的方法是否可以改变返回值的类型?Overload 是重载的意思,Override 是覆盖的意思,也就是重写。重载 Overload 表示同一个类中可以有多个名称相同的方法,但这些方法的参数列表各不相同(即参数个数或类型不同)。
12380
2019-04-17 16:37:29

Java学习中关于并发编程的问题总结
Java编程开发学习需要掌握的知识点很多,并发编程作为Java学习中的难点,也是实际应用中最常用的。编写优质的碧昂发代码并不是一件容易的事情。但是如果我们对并发编程有了更多的认识和实践,就会有更多的方案和更好的选择来实现并发编程。下面就是针对Java学习中关于并发编程的问题总结。
12091
2019-08-08 14:08:47

Java项目实战值得推荐的有哪些?
对于Java编程语言的学习者来讲,最重要的学习环节莫过于进行实战项目的演练。有时候就算你把Java的语法知识背的滚瓜烂熟,也不如参与一个开发项目来获得更快的成长。那么,Java项目实战值得推荐的有哪些?下面我就和大家好好介绍一下博学谷Java就业班的必做项目实战,感兴趣的朋友可以一起来看看。
8183
2020-03-10 20:05:43

0基础自学Java可行吗?
0基础自学Java可行吗?这个问题没有人可以打包票告诉你一个准确的答案,毕竟每个人的学习能力和天赋都是不一样的,但是有一点可以确定,只要找准了方向,愿意踏踏实实的努力学习,完全0基础也可以学好Java。因此对于零基础的学习者而言,要思考的不是自己行不行,而是应该怎么做。只有在摆正了学习心态的基础上,我们才能来讨论自学Java的相关问题。
6539
2020-04-17 18:55:52
Java基础之for循环使用练习
Java语言与现实生活是紧密联系的,因此在Java语言中也有让代码重复执行的循环结构。其中Java开发中使用最多的是 for 循环,并非它有多特殊,知识习惯而已。比如有一个需求:把“爱的魔力转圈圈”输出5遍。你当然可以写5次输出语句,但是太low,也过于冗杂。下面我们来讲讲for循环,然后再做一做相关的使用练习。
6532
2020-08-18 12:24:49



