

课程简介
DMP 全称数据管理系统, 为广告系统提供数据服务, 其中涉及标签处理, 用户识别, 图计算等技术点, 可以帮助提升大数据开发能力.
课程亮点
1.采用Spark + Kudu 方案
以往在使用流式平台处理数据的时候, 数据落地是一个很大的问题, 本课程中详细介绍了能够低延迟处理读写请求的 Kudu 和 Impala. 使用 Kudu 和 Impala 快速的应用查询.
2. 使用 GraphX 进行图计算
深入图计算的场景进行说明, 详细讲解 GraphX 的使用和原理, 使用图计算对数据集进行统一的用户识别
3.报表计算和展示
项目提供详细的报表数据计算和展示说明, 有助于理解报表的流程
项目特色
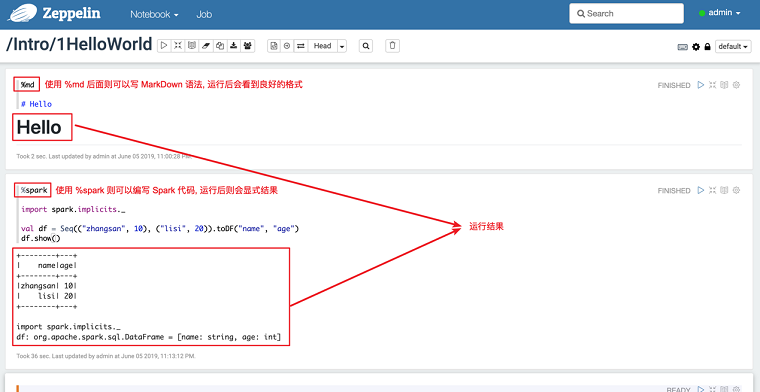
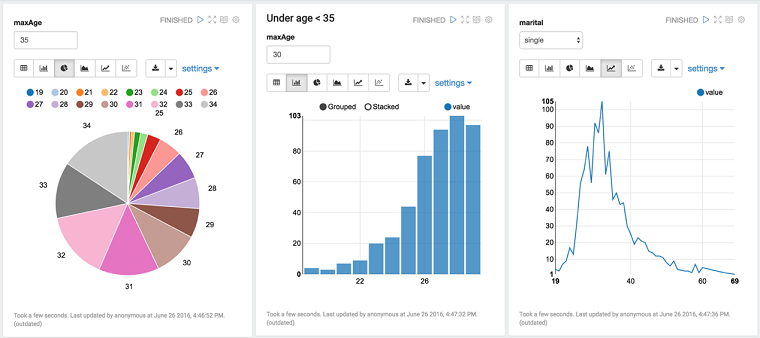
适用人群及技术储备
适合人群
1.JAVA工程师
2.使用其他面向对象语言工程师
3.大数据工程师
技术储备
1.了解 Spark 的使用
主讲内容
第一部分:Kudu 入门
常见的大数据应用场景
常见的数据存储系统对比
Kudu 的总体设计
CDH 各个组件的作用
CDH 版本的安装和搭建
Kudu 的 Java API
Kudu 和 Spark 的整合
第二部分:广告业务
常见的广告项目
广告行业的发展变迁
广告行业各个参与者
AdExchange 和 AdNetwork
DMP 和 DSP 的区别
第三部分:Spark ETL
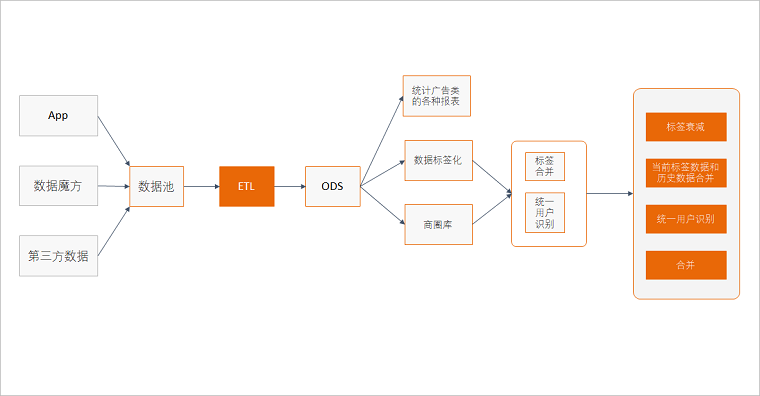
整体框架设计和搭建
整体项目的结构介绍
使用 Spark 进行 ETL
报表统计
数据标签化
商圈库
标签合并
第四部分.图计算
图计算介绍
GraphX 介绍
GraphX 的常见使用方式
GraphX 的原理介绍
统一用户识别
标签衰减和合并
历史数据
第五部分:部署和可视化
Zeppelin 介绍
Zeppelin 安装
使用 Zeppelin 进行数据可视化
Azkaban 部署和调试
课程收获
1. 全面提升 Spark 编程能力
2. 全面理解大数据处理流程
3. 深入了解图计算
4. 全面了解 Kudu 存储引擎以及其使用
师资团队
-
 黑马大数据讲师讲师多年JavaEE开发及编码经验,曾主导多个项目开发,熟悉SpringMVC、MyBatis、Spring等JavaWeb技术,具有多年大数据开发经验,对大数据领域中的常用框架hadoop、hive、flume、kafka、storm、spark等有丰富的实战经验和研究。授课风格严谨,课堂气氛活跃。
黑马大数据讲师讲师多年JavaEE开发及编码经验,曾主导多个项目开发,熟悉SpringMVC、MyBatis、Spring等JavaWeb技术,具有多年大数据开发经验,对大数据领域中的常用框架hadoop、hive、flume、kafka、storm、spark等有丰富的实战经验和研究。授课风格严谨,课堂气氛活跃。



