| 课程参数 | |
|
教学服务
|
随到随学
随时随地皆可学习,无需等待,使你的学习更灵活,更高效。
学前测试
基本信息调查和基础测试,全面了解学前情况,为你制定更适合的学习内容和方法。
专属学习档案
导师时刻关注学习效果,随时指导修订学习路径,全面记录你的专属学习历程。
班主任督导
班主任全程跟进,提供全方位暖心服务,为你的学习保驾护航。
每周学习反馈
每周反馈你的学习数据,提供针对性的指导,关注你的每一个进步,使学习更有动力。
闯关式学习
进阶式地达成每一个目标,不断提高成就感,稳扎稳打,完成课程。
答疑辅导
答疑解惑,及时扫清学习过程中的障碍,助你顺利完成学习。
作业批改
批改作业,指出问题,发现你的薄弱环节,提出建议,使你更有重心的学习。
全方位学习测评
小节测试、课后练习,阶段作业多维度测评,有效保障你的学习效果。
问答讨论
提供高效便捷的答疑平台,与同伴互相交流和借鉴,提升自己。
大咖分享
业界大牛解读前沿技术及其背后的工作原理,拓宽你的眼界。
配套教辅
高度契合的配套讲义、大纲,保证让你全方位的理解知识。
源码开放
提供全部课程源码,搭建真实的开发环境,保证你的练习更高效。
就业服务
一对一职业规划,就业指导,为你高薪就业保驾护航。
学习报告
记录学习轨迹和学习掌握情况,真实全面地体现你的综合学习成果。
结业证书
以官方名义提供的学习经历和成果证明, 是对你能力的肯定和获得企业认可的敲门砖。
作业点评
讲解作业设计思路、点评学员作业问题并给出最终解决方案
入学须知
帮助你更快速的进入学习状态。
集中答疑
定期收集和解答你的技术问题,助你顺利完成学习。
就业指导
简历指导,面试辅导,帮你解惑面试问题。
课程更新
在服务期内,如果课程有更新,你可以享受更新后的课程内容。
|


本套课程覆盖“以机器学习技术栈完成数据挖掘任务,以深度学习技术栈完成NLP自然语言处理”等主流领域;并提供综合项目实战让学生真正掌握 “企业级数据挖掘、自然语言处理等解决方案 ”,为了保障学生就业后竞争力的提升,研发多个人工智能CV方向进阶提升项目课程,如:实时人脸识别、人脸支付、智慧交通、多模态项目等。成为全能的企业级人工智能开发人才。
学完收获 : 能够熟练掌握人工智能开发的通用技术和框架,具备人工智能领域内机器学习,深度学习,自然语言处理和计算机视觉业务分析及开发的能力,同时培养学生使用AI算法构建业务流的能力和针对特定算法进行实用化、拓展化的再创新能力,足以胜任算法工程师等相关AI职位。

队,高标准支撑
课程升级更新
精技术的人工
智能研发工程师
合理,适合AI
技术初学者
新标准,培养
AI专精人才

学完后具备如下能力: 1. 掌握Python开发环境基本配置; 2. 掌握运算符、表达式、流程控制语句、数组等的使用; 3. 掌握字符串的基本操作; 4. 初步建立面向对象的编程思维; 5. 熟悉异常捕获的基本流程及使用方式; 6. 掌握类和对象的基本使用方式。
学完后具备如下能力: 1. 掌握网络编程技术,能够实现网络通信; 2. 知道通讯协议原理; 3. 掌握开发中的多任务编程实现方式; 4. 知道多进程多线程的原理。
缺失值处理:缺失值处理介绍、缺失值数量统计、缺失值可视化、删除缺失值、填充缺失值;
整理数据:melt整理数据、widetolong整理数据;
Pandas数据类型:Pandas数据类型简介、数据类型转换、分类数据类型;
apply函数:Series和DataFrame的apply方法、apply使用案例;
Pandas透视表:透视表概述&会员存量增量分析、会员增量等级分布、增量等级占比分析&整体等级分布、线上线下增量分析&地区店均会员数量、会销比计算、连带率计算、复购率计算;
Datetime数据类型:日期时间类型介绍、提取日期分组案例、股票数据处理、datarange函数、综合案例;
学完后具备如下能力: 1. 掌握Pandas案例; 2. 知道绘图库使用; 3. 掌握Pandas数据ETL; 4. 掌握Pandas数据分析项目流程。
学完后具备如下能力: 1. 掌握机器学习建模流程; 2. 知道Sklearn机器学习库使用; 3. 掌握常见的机器学习分类、回归、聚类算法; 4. 掌握机器学习常见应用场景。
学完后具备如下能力: 1. 掌握金融风控相关业务知识; 2. 掌握机器学习项目特征工程通用方法; 3. 掌握评分卡建模特征工程方法; 4. 掌握评分卡模型构建、调优与监控方法; 5. 掌握常用异常点检测算法的应用; 6. 掌握模型解释常用方法。
学完后具备如下能力: 1. pytorch工具处理神经网络涉及的关键点; 2. 掌握神经网络基础知识|3.掌握反向传播原理; 3. 了解深度学习正则化与算法优化。
学完后具备如下能力: 1. 掌握NLP领域前沿的技术解决方案; 2. 了解NLP应用场景; 3. 掌握NLP相关知识的原理和实现; 4. 掌握传统序列模型的基本原理和使用; 5. 掌握非序列模型解决文本问题的原理和方案; 6. 能够使用pytorch搭建神经网络; 7. 构建基本的语言翻译系统模型; 8. 构建基本的文本生成系统模型; 9. 构建基本的文本分类器模型; 10. 使用ID-CNN+CRF进行命名实体识别; 11. 使用fasttext进行快速的文本分类; 12. 胜任多数企业的NLP工程师的职位。
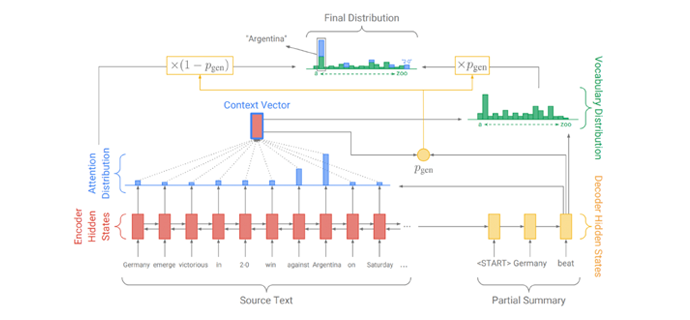
学完后具备如下能力: 1. 掌握人工智能处理原始数据到模型所需数据的全流程; 2. 掌握抽取式摘要模型textRank的实现流程和原理; 3. 掌握如何利用gensim工具训练word2vec词向量; 4. 掌握垂直领域词向量训练的经验和技能; 5. 掌握经典seq2seq架构完成文本摘要任务; 6. 掌握前沿PGN架构完成文本摘要任务; 7. 掌握评估生成式任务的BLEU算法和ROUGE算法理论和实现; 8. 掌握coverage机制的原理和实现; 9. 掌握beam-search的原理和实现; 10. 掌握单词替换, 回译数据, 半监督学习等主流数据增强的算法; 11. 掌握Scheduled Sampling和Weight Tying的训练策略优化; 12. 掌握AI模型的硬件部署优化, GPU部署, CPU部署等等。
学完后具备如下能力: 1. 掌握人工智能处理原始数据到模型所需数据的全流程; 2. 掌握抽取式摘要模型textRank的实现流程和原理; 3. 掌握如何利用gensim工具训练word2vec词向量; 4. 掌握垂直领域词向量训练的经验和技能; 5. 掌握经典seq2seq架构完成文本摘要任务; 6. 掌握前沿PGN架构完成文本摘要任务; 7. 掌握评估生成式任务的BLEU算法和ROUGE算法理论和实现; 8. 掌握coverage机制的原理和实现; 9. 掌握beam-search的原理和实现; 10. 掌握单词替换, 回译数据, 半监督学习等主流数据增强的算法; 11. 掌握Scheduled Sampling和Weight Tying的训练策略优化; 12. 掌握AI模型的硬件部署优化, GPU部署, CPU部署等等。

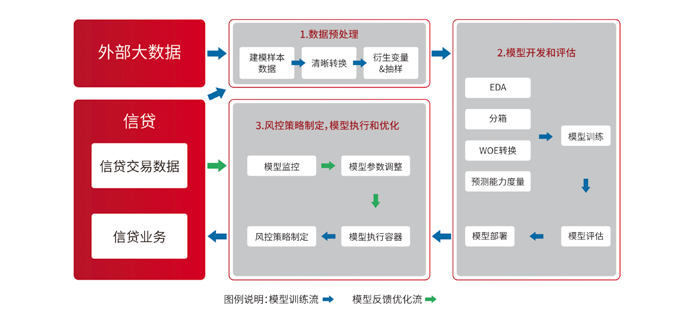
传统金融由于风控审批主要靠人工进行,审批速度慢,一般只服务大公司,或者收入较高的人群,很多低端、无稳定收入的群体和小微企业无法享受到传统金融服务。面临如此庞大的市场,小额贷款作为新型的金融服务产品应运而生,小额贷款业务具有单笔金额小、单笔利润低、利润率高、审批速度快的热点,所以基于用户申请信息的快速自动审批系统(风控系统)就成了互联网金融领域核心的竞争力。金融风控项目搭建了整套金融风控知识体系,从反欺诈、信用风险策略、评分卡模型构建等热点知识,使得学员具备中级金融风控分析师能力。
技术亮点:
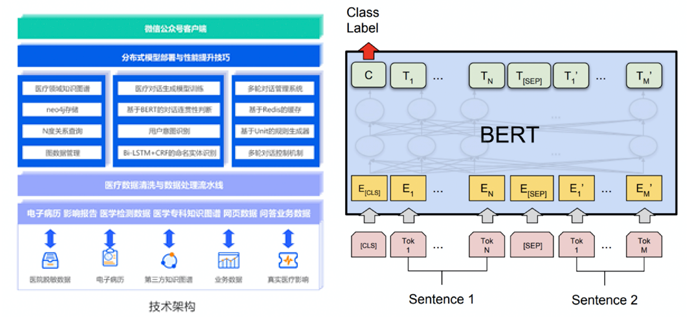
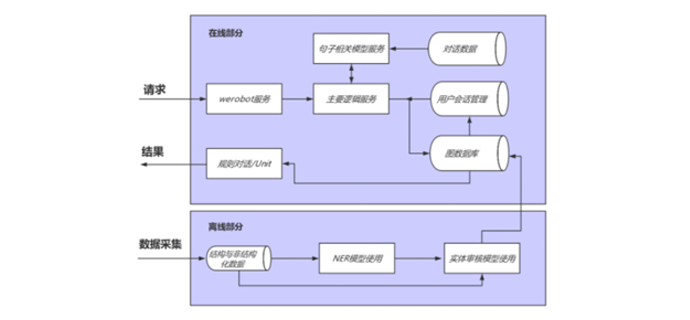
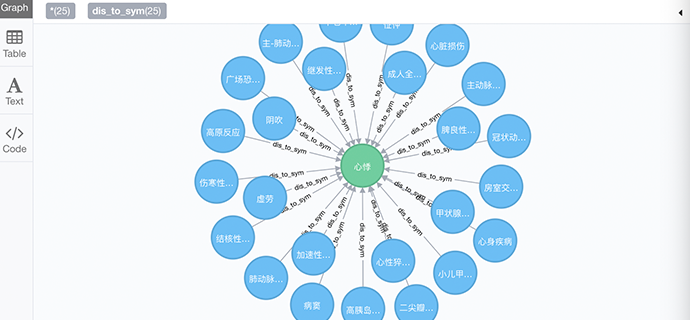
该项目结合医学知识图谱、深度学习、对话管理、微信公众号开发等技术,旨在降低首医成本,为患者提供基本医学诊断意见服务。技术层面包含语音识别、自然语言理解、对话管理以及自然语言生成等环节,其中又包含领域识别,用户意图识别,槽位填充,对话状态追踪,对话策略等技术细节。功能上为患者提供根据症状信息给出诊断意见任务与就近治疗任务。通过学习该课程,学生可以了解多轮多任务对话系统的技术点以及业务流程。
技术亮点:
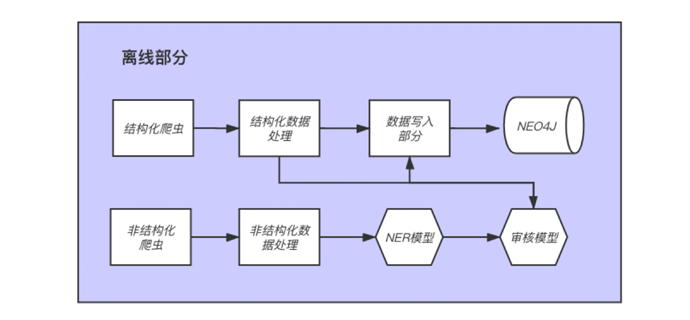
文本摘要项目是一个基于NLP底层基础任务的全流程实现项目。在工业界有广泛应用,比如四六级的阅读理解考试,新浪体育的球评新闻,今日头条的新闻快递,金融简报等等。涉及到互联网场景下海量的大段文本的信息压缩和融合技术,可以让人们在信息爆炸的时代快速浏览重要信息。通过本项目的学习,可以掌握工业界最主流的处理文本摘要的模型和优化技术。这里面关于解码方案的优化,数据增强的优化,还有训练策略的优化,无论是理论还是代码,都可以非常方便的迁移到未来企业级的开发中。同时在部署方案上,掌握GPU部署和CPU部署的相同点和不同点。
技术亮点: